













过去十几年,几乎所有增长讨论,最终都会回到一个问题:流量从哪里来。
在这个问题上,行业已经形成了高度共识的三种基本形态:推荐流量、搜索流量、社交流量。

推荐流量,来自算法分发。它的优势极其明显——起量快、爆发强,一条内容、一轮投放,可能在极短时间内带来远超预期的曝光。但它的短板同样致命:生命周期短、波动性大,对平台规则和算法高度依赖。一旦推荐衰减,流量几乎同步归零。它更像一次性红利,而不是长期资产。
搜索流量,来自主动需求。用户不是被“推到你面前”,而是带着明确问题来找答案。这决定了它天然具备两个特征:转化率高,以及长尾效应强。一个被反复搜索的问题,只要需求端稳定存在,就能持续产生流量。它不依赖情绪刺激,而依赖信息匹配,增长曲线不陡峭,但足够持久。
社交流量,建立在信任之上。它往往来自熟人关系、社群影响、KOL 背书或长期内容输出。它的转化效率极高,但启动门槛同样很高——需要时间、关系密度和持续经营。一旦信任建立,复利效应明显;但在冷启动阶段,几乎无法规模化。
这三类流量,本质上对应了几种完全不同的不确定性结构。
推荐流量的不确定性在“是否被算法青睐”;社交流量的不确定性在“是否被信任”;而搜索流量,恰恰相反,它是一种确定性极强的流量形态。
只要用户的问题真实存在,只要关键词被反复提出,只要信息供给能够准确命中,搜索流量就一定成立。
找到确定性的需求词,用确定性的方法论,占据确定性的入口,获取可预期的流量回报。
正因为这种确定性,过去二十年里,几乎每一次互联网红利的释放,都伴随着一次“搜索形态”的升级。
我们可以把它概括为四个连续演进的阶段,我们称之为“4O”。

第一阶段,是以网页为中心的 SEO(Search Engine Optimization)。
核心问题是:如何在搜索引擎的结果列表中获得更高排名。
第二阶段,是以 APP 生态为中心的 ASO(App Store Search Optimization)。
搜索不再发生在浏览器,而是发生在应用商店,竞争对象从网页变成了 APP。
第三阶段,是以内容平台为中心的 DSO(Douyin Search Optimization)。
搜索开始进入超级 APP 与内容平台内部,搜索结果不再是传统的链接列表,而是以信息流的形式直接呈现内容。
而第四阶段,正是正在发生的 GEO(Generative Engine Optimization)。
搜索不再返回“结果内容”,而是直接生成“答案”。用户面对的,不再是一组可供点击的链接,而是一段已经被整理、压缩、判断过的结论。
在 SEO、ASO、DSO 时代,系统做的是“筛选与排序”,最终判断仍然由用户完成。
而在 GEO 时代,系统开始直接给出判断本身。
这意味着,搜索的竞争位置,正在从“结果页”整体前移到“答案生成层”。
品牌不再只需要被“看到”,而是需要被 AI 系统理解、引用、采信。
正是在这样的背景下,本报告试图回答一组绕不开的问题:
AI 搜索是否已经变成了用户的"默认入口"?
当用户向 AI 提问时,他们真正想要的是什么——是答案,还是决策框架?
品牌在 AI 的回答中,是如何被纳入、比较、筛选与信任的?
用户会因为 AI 的推荐而改变原有选择吗?这种影响力的真实边界在哪里?
对企业而言,GEO 究竟是概念炒作,还是可验证的增长机会?落地的真实障碍又是什么?
为了回答这些问题,我们于近期开展了一项针对中国市场 AI 搜索使用行为与 GEO 认知的专项调研。
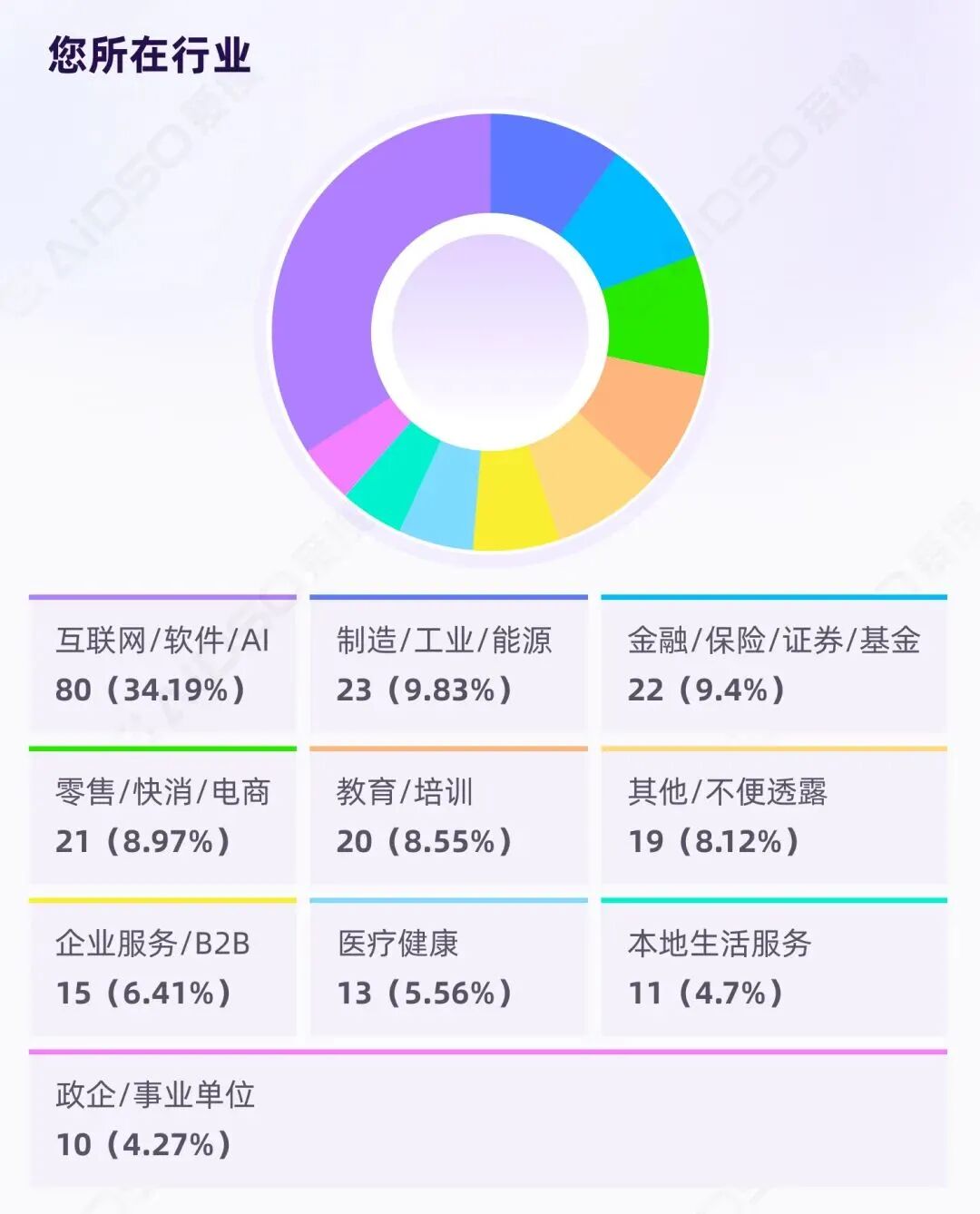
本次调研共回收有效样本 234 份。
受访者覆盖互联网/软件/AI(34.19%)、
制造/工业/能源(9.83%)、
金融/保险/证券(9.40%)、
零售/快消/电商(8.97%)、
教育/培训(8.55%)等十余个行业,同时涵盖企业服务、医疗健康、政企单位、本地生活服务等细分领域。

从岗位角色看,
市场/品牌/公关/运营人员占比最高(27.78%),
其次是销售/BD/渠道(19.23%)、
企业高管/创始人(17.09%)、
产品/研发/技术(13.25%)、
采购/行政/财务(10.26%)。
这一结构确保了调研既能捕捉到营销决策者的视角,也能反映企业管理层和业务一线的真实认知。
接下来的内容,将基于这 234 份真实样本,系统拆解 AI 搜索正在如何重塑用户的决策路径、信任机制与品牌可见度结构,并在此基础上,明确 GEO 在当下阶段的真实价值、组织落地的核心障碍,以及可执行的行动边界。

我们一直以为 AI 搜索习惯的迁移"正在发生",其实"已经发生"。至少在我们触达的这批用户中,AI 搜索早已不是新鲜事物——它已经变成日常决策的基础设施,像水电一样融入日常。
1.1 搜索入口的结构性迁移
先看一个基础问题:现在大家都去哪里搜索?
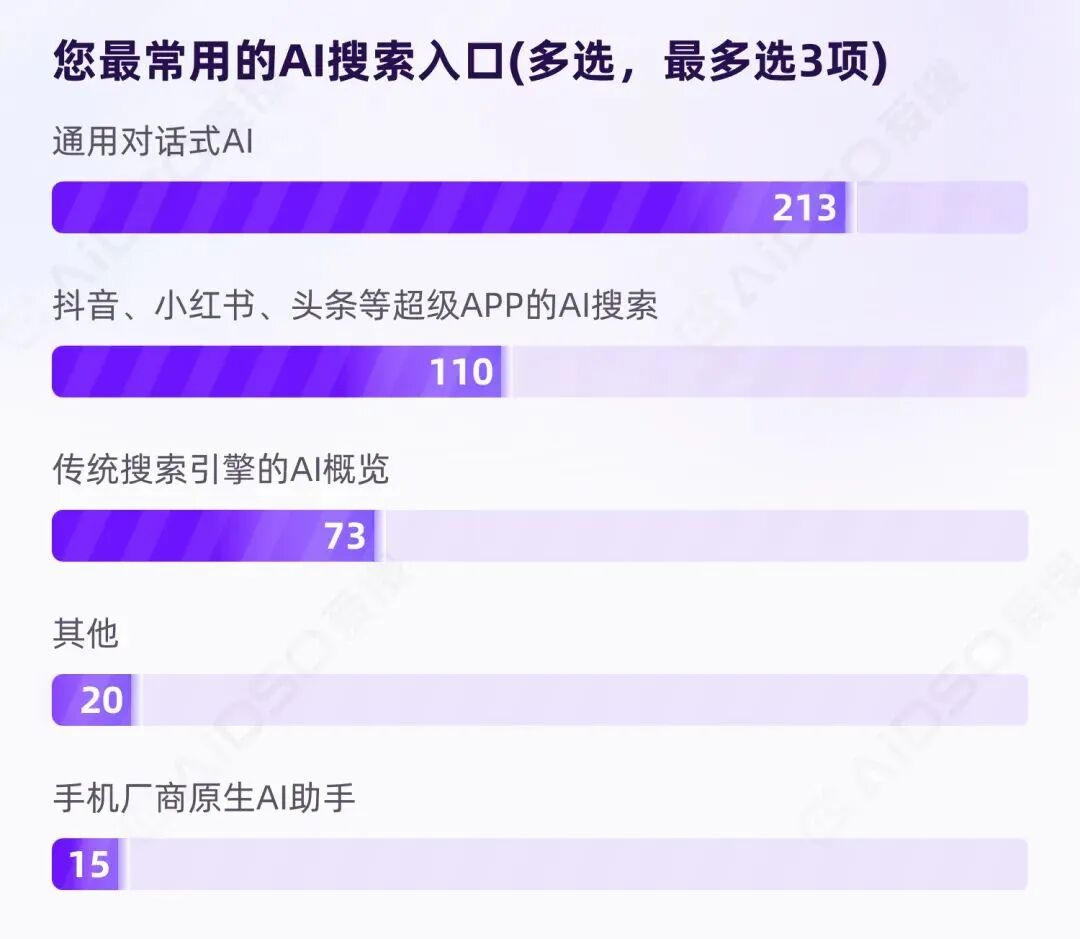
234 份有效问卷中,受访者共勾选 431 次,人均使用 1.84 个 AI 搜索入口,搜索行为呈现高度碎片化。
从具体分布看,搜索入口呈现清晰的三层结构:
第一层:通用对话式 AI——91%覆盖率
豆包、DeepSeek、Kimi、通义等通用对话式 AI,获得 213 次选择,对应 91%的人群覆盖率。这不是"排名第一",而是接近"全民级"渗透。
这直接改写了品牌可见度的规则。过去 SEO 的核心目标是点击率,但在 AI 对话场景中,用户看到的是整合后的回答,而非待点击的链接。竞争焦点从"能否被点击"转向"能否被 AI 吸收、复述、引用"。如果品牌不在模型的可引用信息池里,在这 91%的搜索场景中就是隐形的。
第二层:超级 APP 内置 AI 搜索——47%覆盖率
抖音、小红书、头条等超级 APP 的 AI 搜索功能,覆盖 47%的受访者。这一层是强场景入口,集中承接消费决策、经验判断类需求。
在这些平台上做 GEO,逻辑与网站 SEO 完全不同。平台内 AI 在自有内容生态中检索整合,核心竞争力是内容资产、账号权重与互动信号的叠加——平台内可信度、可验证的真实案例、用户互动数据,才是关键变量。
第三层:传统搜索引擎的 AI 概览——31%覆盖率
百度等传统搜索引擎的 AI 摘要功能,仍覆盖 31%人群。虽然增长势头让位于前两层,但它承担着公共信息与权威来源的上游供给角色。
传统搜索引擎积累的网页索引和权威性判断机制,仍是许多 AI 模型引用的重要原料。忽视这一层,不仅失去直接触达机会,更可能削弱品牌在第一层的稳定性——因为通用 AI 往往间接依赖这些上游来源。
1.2 高频使用已成常态
入口迁移回答了"去哪里搜"的问题。更关键的问题是:AI 搜索在用户生活中到底有多重要?
数据给出的答案比预想更明确。
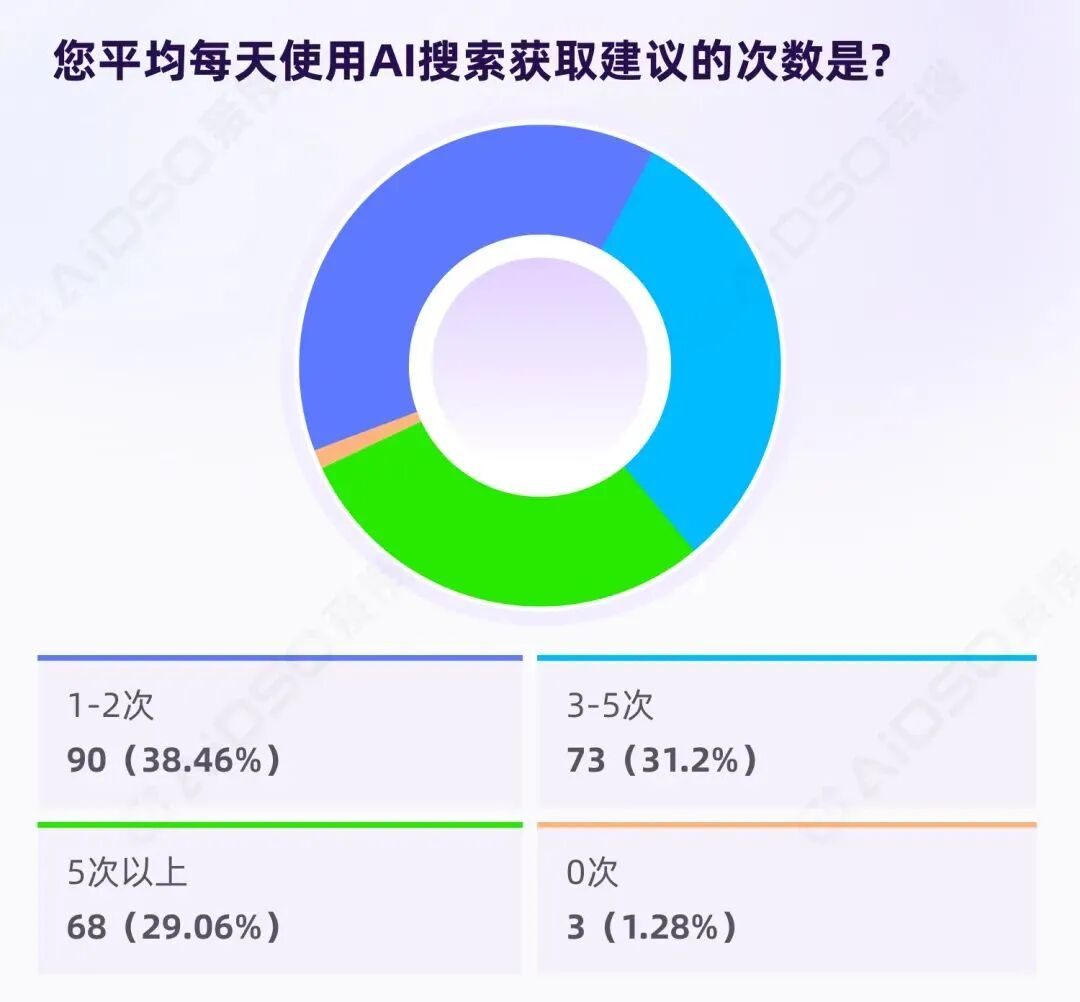
98.72%的用户每天都在使用
234 份样本中,只有 1.28%表示每天使用次数为"0 次"。98.72%的人每天都会使用 AI 搜索获取建议——这不是尝鲜,而是稳定、重复、已嵌入日常的使用习惯。
60%以上每天至少使用 3 次
38.46%的用户每天 1-2 次,把 AI 当"确认器";超过六成的中高频用户每天至少 3 次,把 AI 当"决策操作系统"。综合估算,这批人每天平均使用 AI 搜索约 4 次,AI 已占据高频决策循环的核心位置。
高频使用带来两个必须面对的变化:
问题颗粒度急剧变小。 每天 3 次以上的频率,决定了用户问的都是高度情境化、长尾化的问题。GEO 优化拼的是"场景簇覆盖",而非几个核心关键词。
建议型回答必须可执行。 用户要的是建议,不是百科知识。对比维度、判断阈值、操作流程、风险提示——缺失这些要素,内容就难以被 AI 反复引用。

确认了 AI 搜索已成为基础设施之后,下一个关键问题是:用户到底在用 AI 做什么?AI 又是如何介入并影响他们的决策过程的?
数据显示,AI 在决策中扮演的角色,远比"推荐一个产品"复杂得多,也远远不是"替人做决定"。
2.1 用户向 AI 提出的核心诉求:不是"帮我买",而是"让我懂"
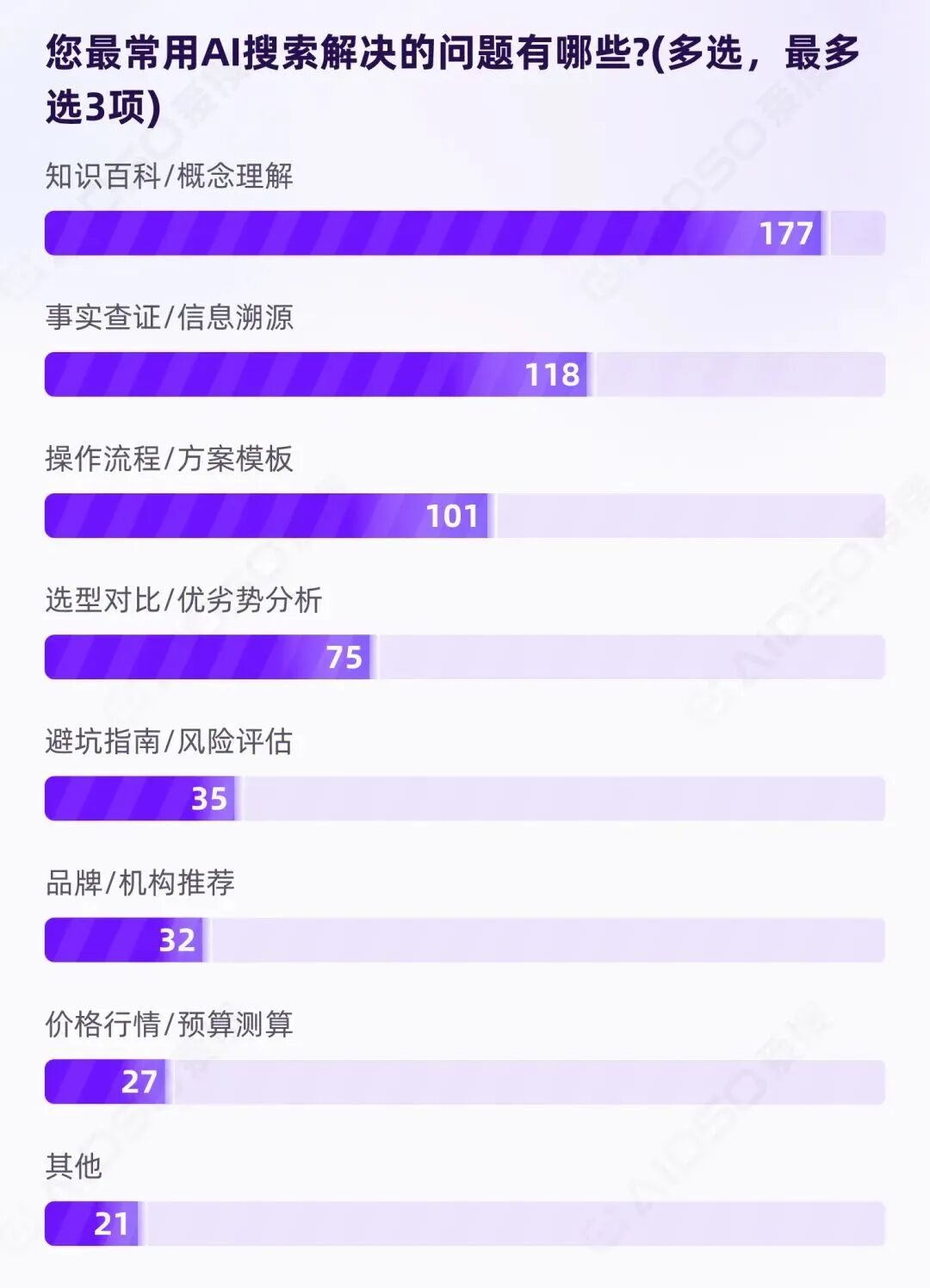
234 名受访者共产生 587 次选择,人均 2.51 项,且至少一半用户直接选满 3 项。
从覆盖率来看,排名前三的需求类型分别是:
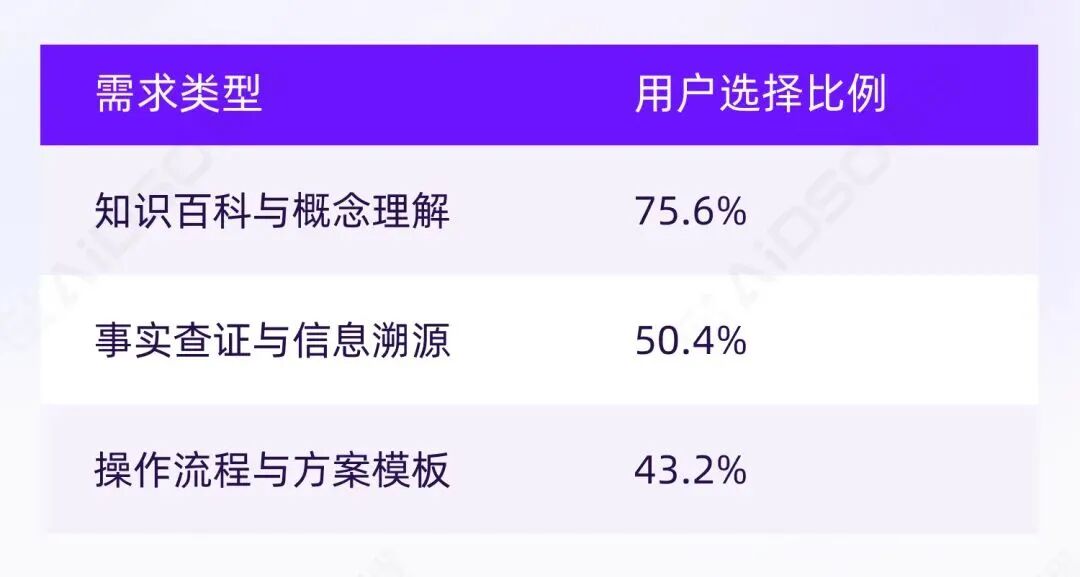
这三类需求合计占到 67.46%的选择次数,远高于选型对比、品牌推荐和价格测算。
AI 在用户心中承担的是一条完整的"认知—验证—执行"生产力链,而非导购链。
用户在进入"选谁""买不买"之前,首先要完成三件事:建立认知模型、校验信息可信度、获取可执行的行动方案。
这对 GEO 优化的要求是:
概念理解需求要求企业提供可被复述的定义与框架——清晰的边界、对比维度和核心判断逻辑
溯源查证需求要求内容从"营销叙事块"升级为"可验证数据块"——明确主张、可验证出处、数据清晰
流程模板需求要求内容工程化表达——步骤、条件、分支、检查表
GEO 优化竞争的不是曝光,而是谁能成为 AI 在解释、引用和生成行动方案时的默认材料。
2.2 AI 推荐优先渗透高决策成本领域:越怕选错,越信 AI
当用户真的让 AI 做推荐时,他们在哪些领域最愿意听从?
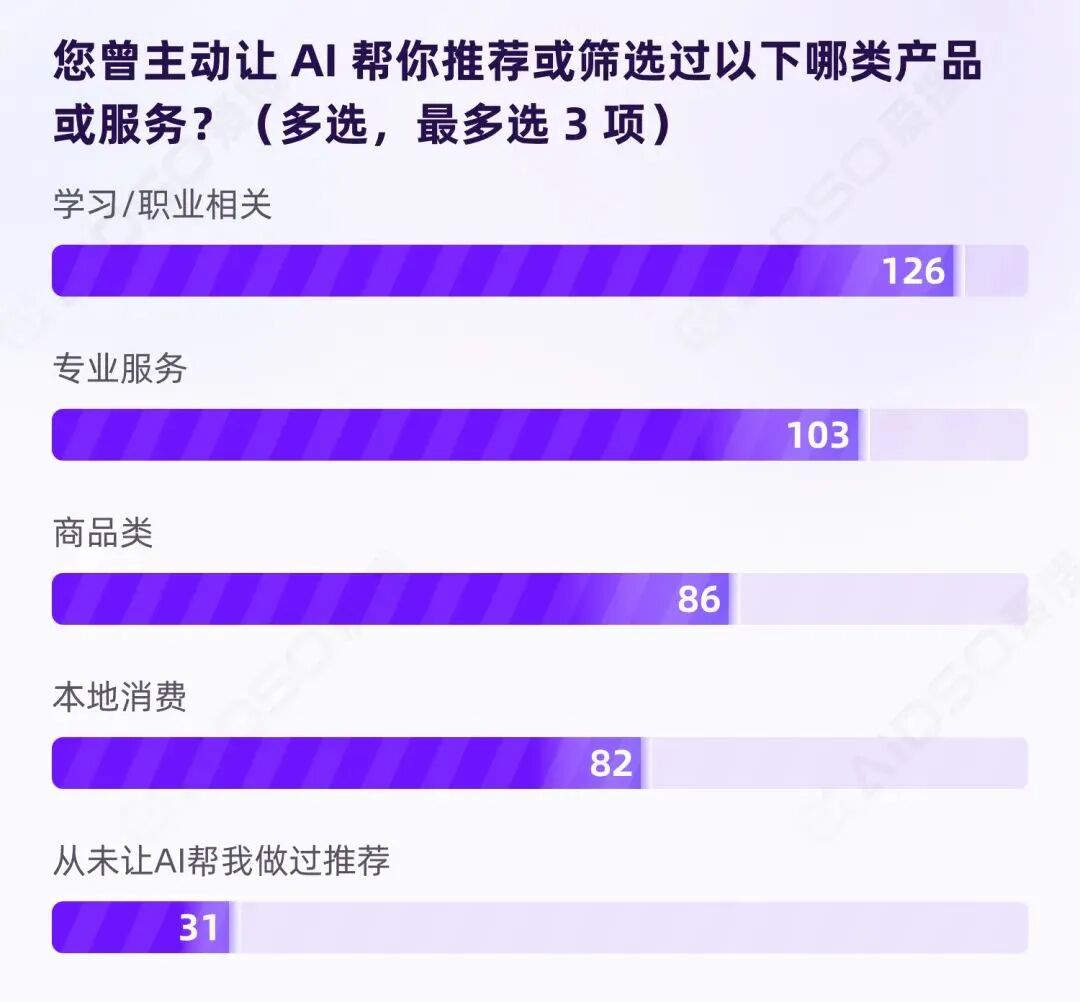
数据显示,仅有 13.2%的受访者"从未让 AI 做过推荐"。
让 AI 参与筛选和缩小选择范围,已经是常态行为,而非偶发尝试。
从具体品类来看,渗透率排序呈现清晰规律:
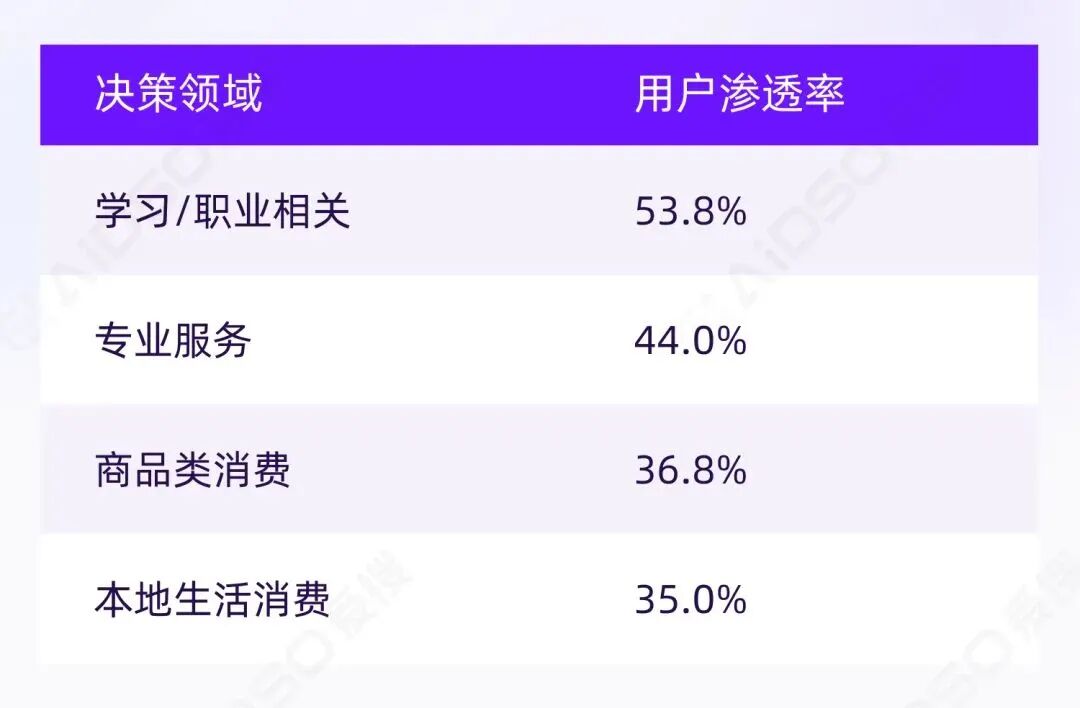
用户最愿意让 AI 推荐的,并不是低风险、可随时试错的消费品,而是试错成本大、信息极度不透明的决策。
这与上一问题得出的结论一致,用户先用 AI 建立认知框架、验证关键信息,然后才进入"帮我筛选"阶段。推荐并非决策的起点,而是决策后段的产物。
AI 推荐正在向高决策成本领域集中,谁能为这些决策提供可信框架,谁才会被稳定推荐。
2.3 AI 影响决策的真实方式:不替你拍板,但帮你划重点
AI 到底是如何影响用户最终选择的?
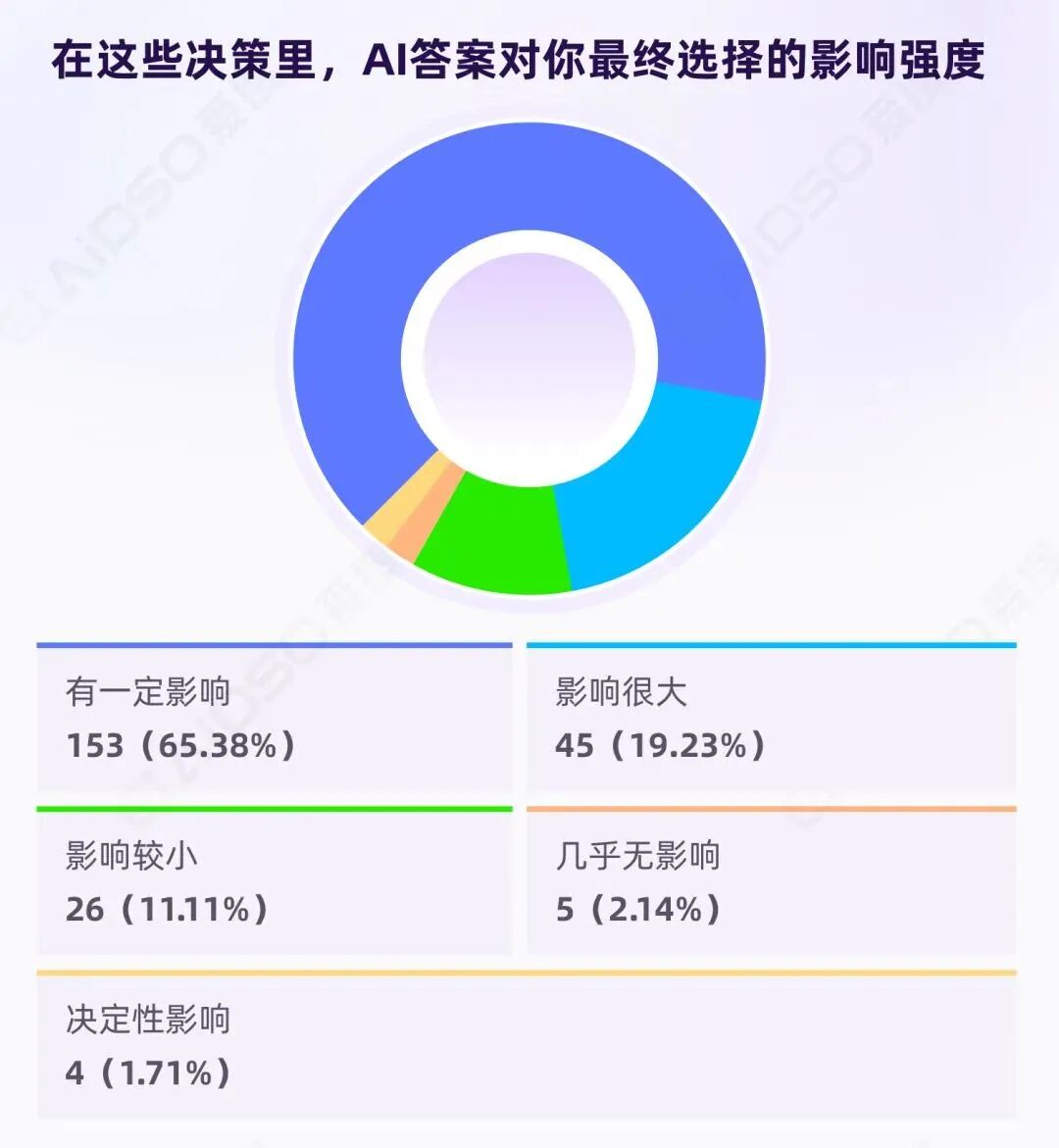
有效样本 233 人,影响强度分布如下:
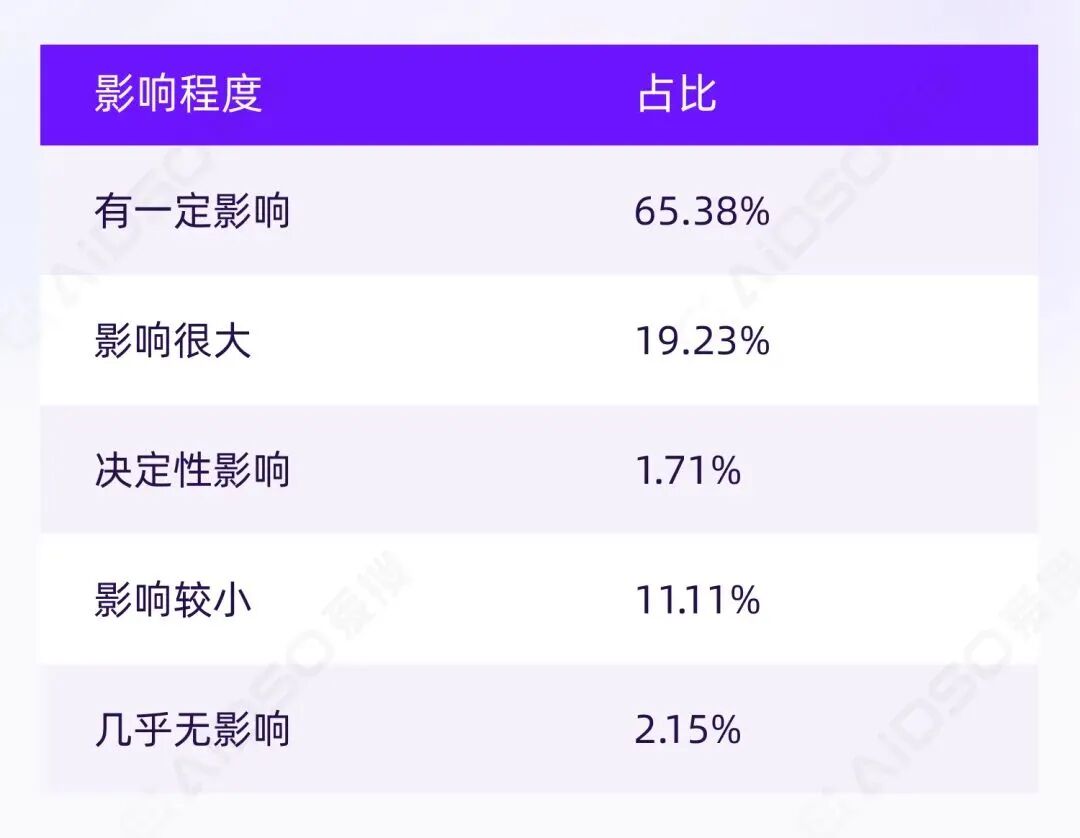
至少有影响的比例达到 86.70%,加权均值约 3.07/5,主峰落在"有一定影响"。
AI 并非替人做最终裁判,而是完成三件事:改变备选集、改变排序、改变信心。
进一步追问影响方式,两种机制占据压倒性主导:
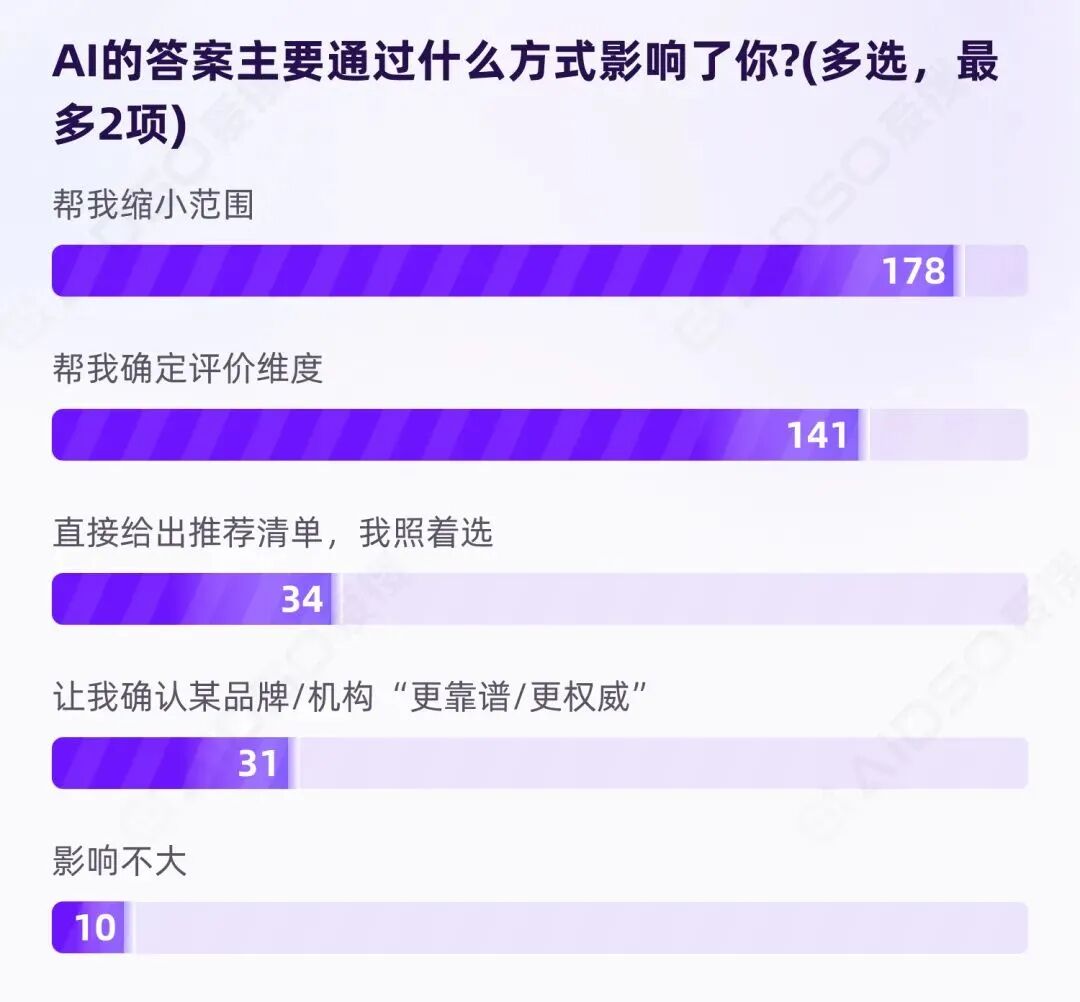
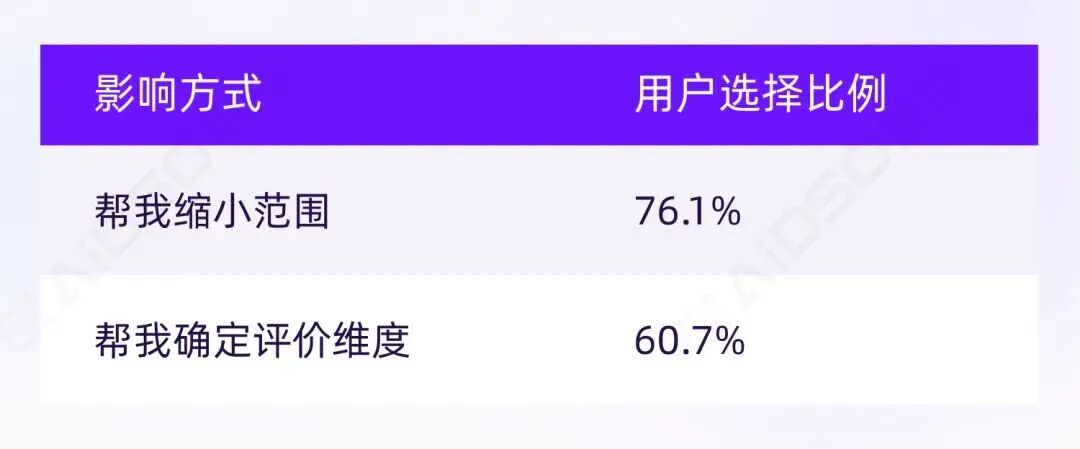
两者合计占 81.01%的选择次数,而"直接给出推荐清单"和"确认某品牌更权威"合计仅约 16.5%。
"缩小范围"决定谁有资格被考虑。 这一步发生在成交之前,却已经决定了谁能进入下一轮比较。
GEO 优化,竞争的第一道关口不再是"谁排第一",而是能否进入 AI 缩小后的短名单。
“确定评价维度"定义什么叫"好”。 当用户面对陌生领域时,AI 给出的评价维度本身就构成了隐性的决策规则。如果你的产品在某一维度具有结构性优势,真正有效的 GEO 优化策略是让 AI 学会:在这个品类里,这一维度应该被优先考量。
GEO 优化真正要争夺的不是"推荐位",而是入围权与评价框架的话语权。
AI 的影响力是真实的,但它的作用方式是"铺路"而非"拍板"——改变的是入围规则和比较逻辑,而不是替人做最终决定。
GEO 优化的目标因此变得清晰:
确保品牌稳定进入 AI 缩小后的候选集
让 AI 在讲解评价维度时,引用你提供的判断标准
在用户核查阶段,提供可验证的证据支撑信任
只有当你的信息被 AI 用来缩小范围、构建比较维度时,你才算真正进入了决策链;否则,即便偶尔被提及,也只会在筛选阶段被系统性淘汰。

用户凭什么相信 AI 给出的答案?
数据显示,用户并非盲目接受 AI 的输出,而是通过引用来源进行核查;能够真正增强信任的,不是流量信号或社交背书,而是可审计、可复核的权威来源;用户对推荐形态的期待,不仅仅是"给我答案",同时也要"教我方法"。
3.1 引用来源:信任跃迁的关键支点
在传统搜索时代,用户信任的锚点是"排名"。但在 AI 对话场景中,用户看到的是一段整合后的回答,信任的锚点转移到了新的位置:引用来源。
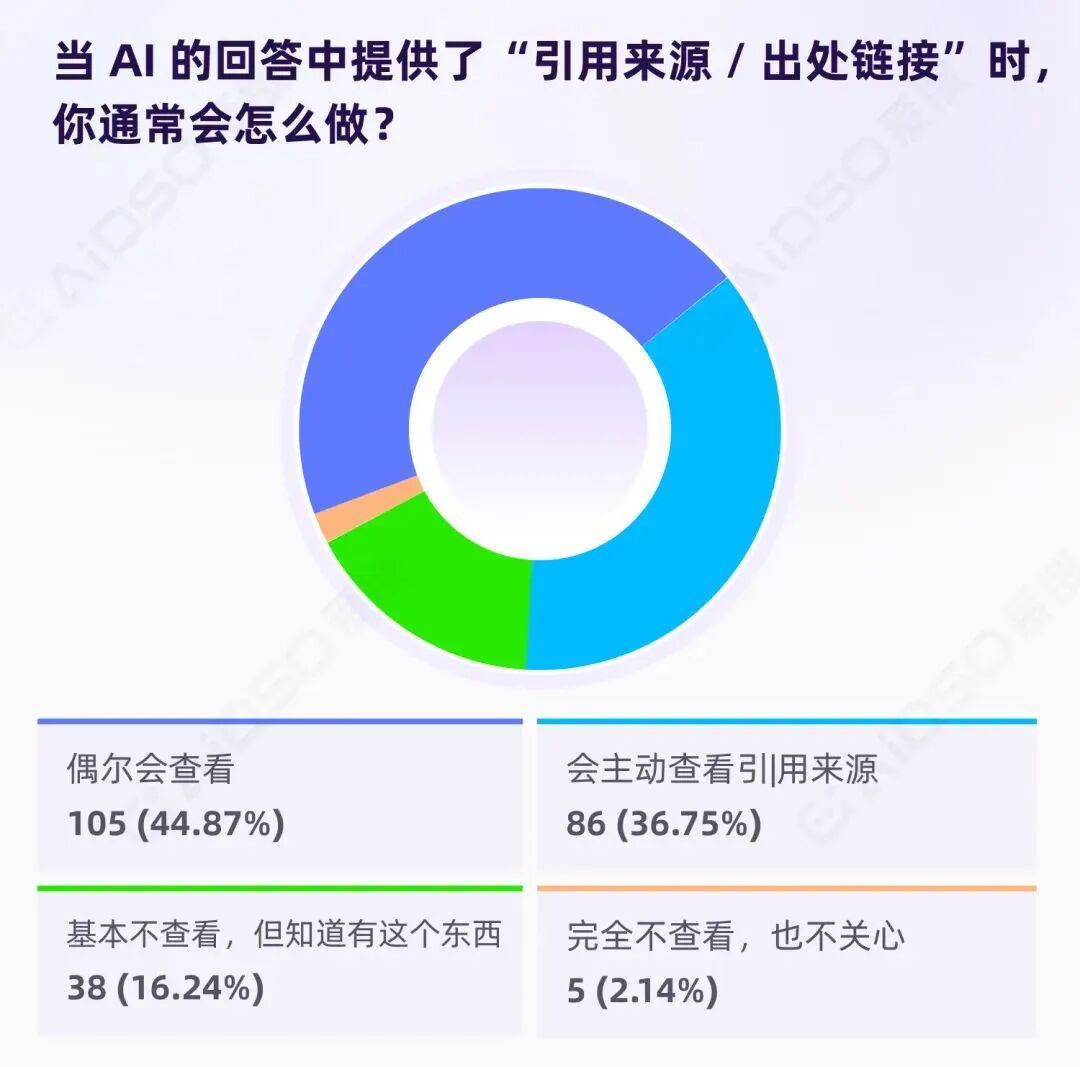
81.62%的用户会查看引用来源。 这彻底否定了"用户只看 AI 结论,不在乎来源"的假设。
为什么引用来源如此重要?因为 AI 的回答本质上是概率输出,用户无法直接判断其可靠性。但当 AI 附上引用来源时,用户获得了核查入口——可以点开链接,判断 AI 的整合是否准确、是否断章取义。
引用链接,是"机器信任"与"人类信任"的交汇点。
这里有一个常被忽略但极其关键的事实:这些被 AI 引用的来源,会被真实的人点开、阅读、核查。 在这个环节,内容质量被直接放到放大镜下:结构是否清晰、逻辑是否自洽、数据是否一致——都会影响信任是否继续向前推进。
被 AI 提及只是第一步,被 AI 引用并附上链接才是信任跃迁的关键。要成为可引用来源,内容必须满足:清晰的内容结构、可被验证的事实数据、可识别的权威性信号。
3.2 AI 正在引用谁:各大引用来源 Top10
AI 现在把引用票投给了谁?
我们统计了 AIDSO 爱搜平台,6 大主流 AI 平台的引用来源数据,总计 498,269 篇被引用文章。结论如下:
全平台引用来源 Top10:
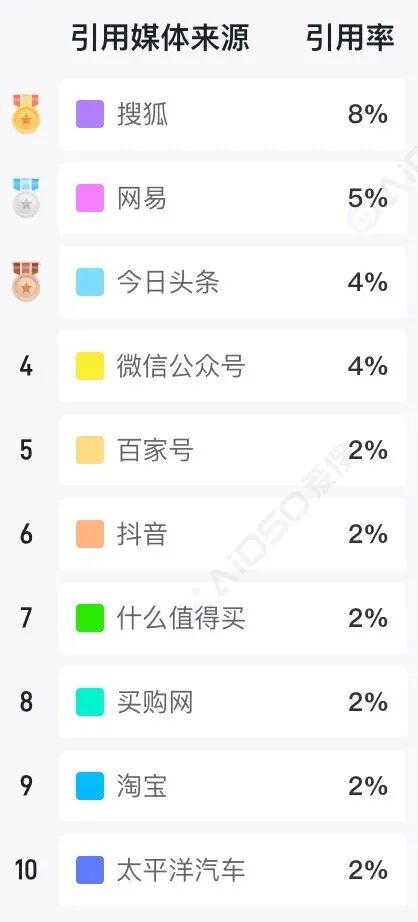
从全平台数据来看,自媒体与内容平台占据了 AI 引用体系的半壁江山,这也是当前 GEO 优化普遍从自媒体平台入手的现实原因。但这种结构只是跨行业的平均态,具体到单一行业和决策场景,引用来源差异显著,必须按行业与问题类型分别分析,不存在一套通用解法。
分平台引用来源 Top10 数据:
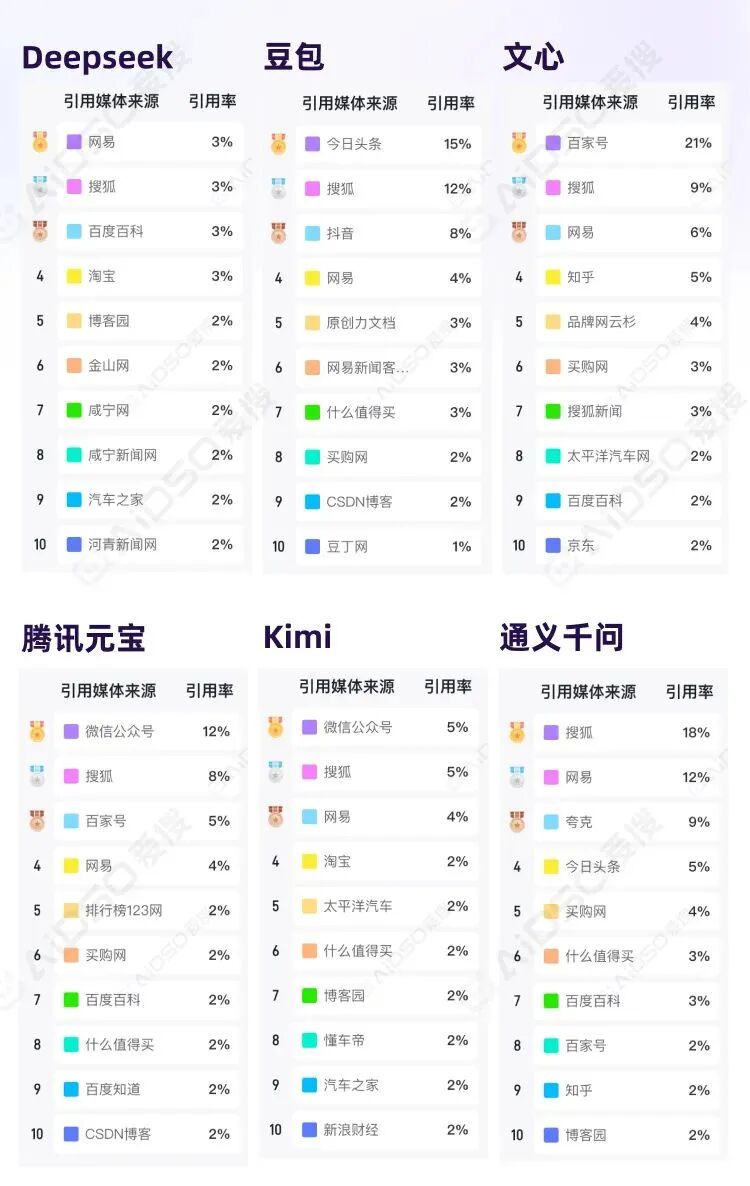
不同 AI 平台的引用偏好差异较大:
豆包:内容平台与资讯平台占绝对主导,同时混入文档站与技术社区。
DeepSeek:百科、电商、技术社区与地方资讯高度混合,来源分散、集中度低,是典型的“杂食型引用结构”。
文心一言:百家号占比显著领先,强烈体现百度自有内容生态的加权与内循环特征。
腾讯元宝:以微信公众号为核心,同时明显偏好百度系知识产品(百家号、百科、知道),呈现“公众号 + 结构化知识”的组合。
通义千问:资讯平台占优,同时出现夸克等自有内容来源。
Kimi:公众号、资讯与垂直内容站点(汽车、财经)并重,整体结构更贴近真实用户的阅读与决策信息源分布。
3.3 时间新鲜度:被引用的隐形门槛
除了来源渠道,还有一个容易被忽视的变量:内容的时间新鲜度。
我们统计了四个数据口径可靠的平台(DeepSeek、腾讯元宝、文心一言、Kimi)在 180 天、90 天、30 天窗口内的被引用文章量。
30 天"新内容占比":用近 30 天文章量除以近 180 天文章量,可以观察"新鲜内容密度":
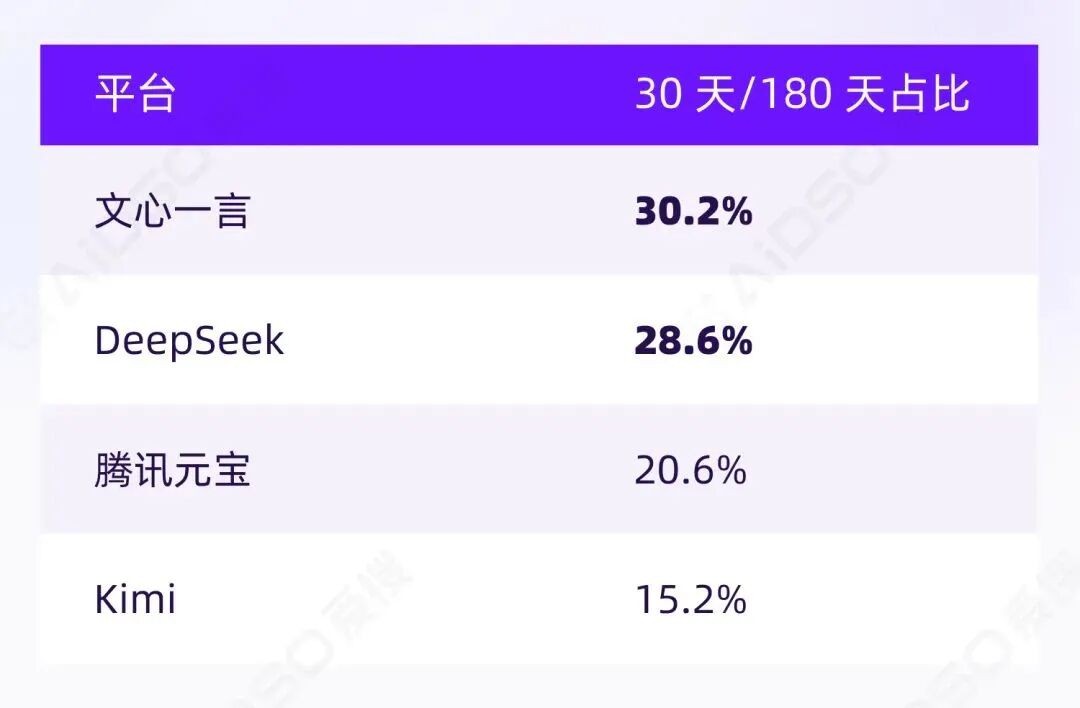
这组数字说明:引用/收录并非"写一次永久有效",而是存在明显的新鲜度权重。尤其是文心与 DeepSeek,近 30 天内容在 180 天窗口内占比接近三成。
3.4 什么来源真正增强信任?
确认了引用来源的重要性之后,下一个问题是:什么类型的来源,能够真正增强用户对 AI 回答的信任?
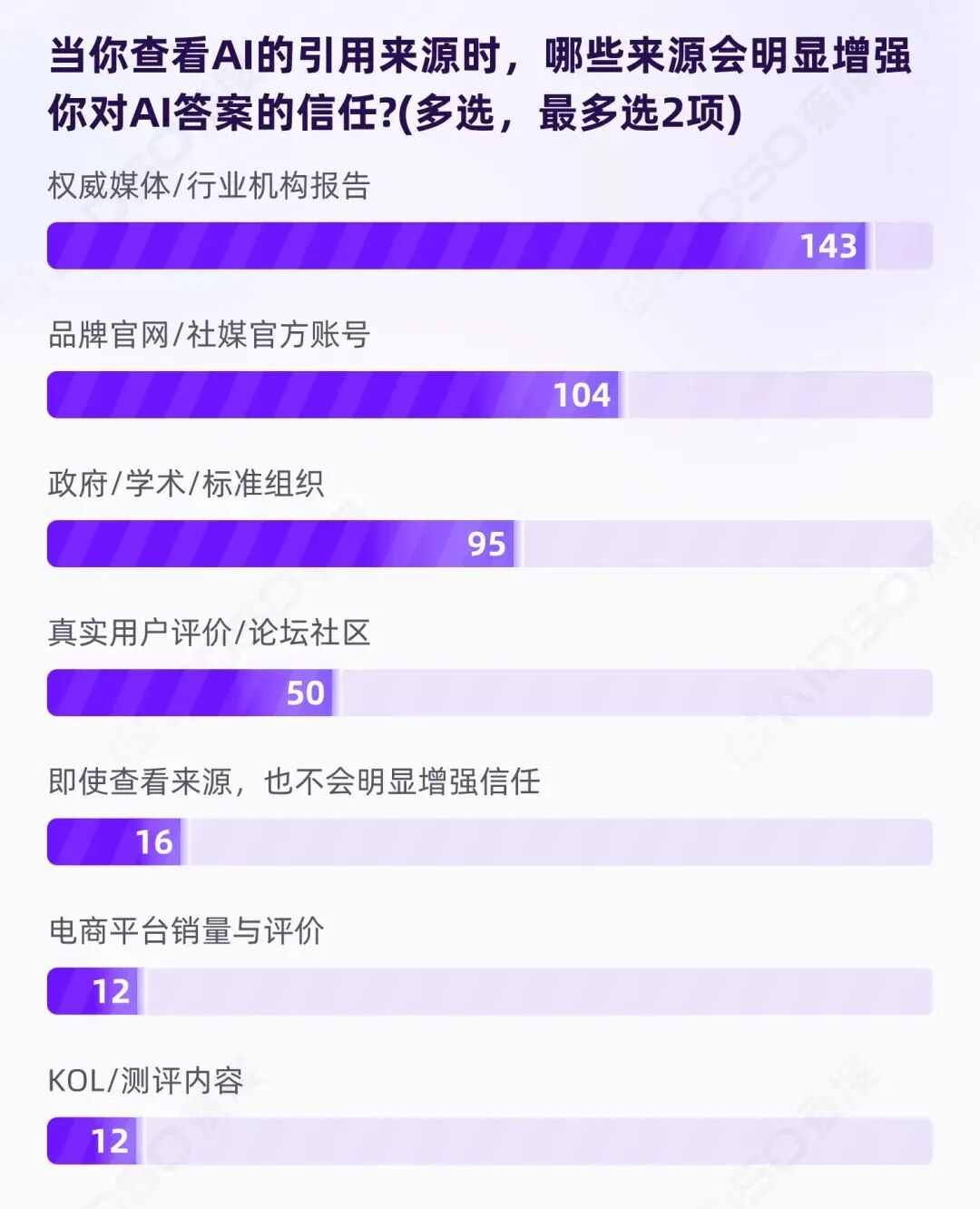
权威媒体与官方网站占据主导,甚至超过了政府/学术网站的内容。调研中请受访者选择哪些引用来源会增强信任(最多选 2 项),234 份样本共产生 432 次选择。覆盖率排名:
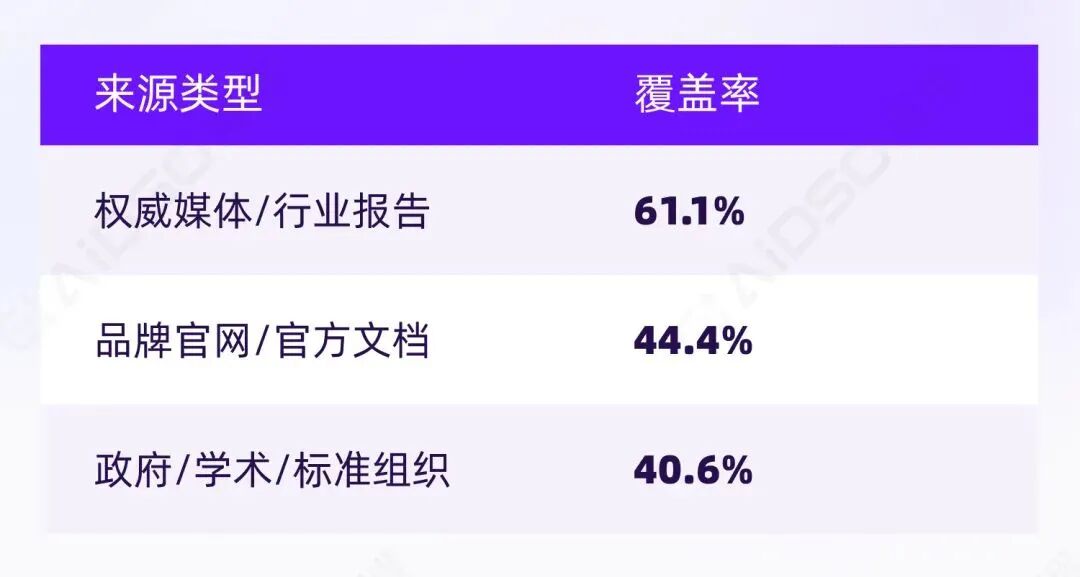
与此形成鲜明对比的是,两类在传统营销中被高度重视的来源,在 AI 信任机制中几乎失效:KOL/达人推荐和电商销量/评价都仅占 5.1%。
信任的底层逻辑,具备三个共同特征:
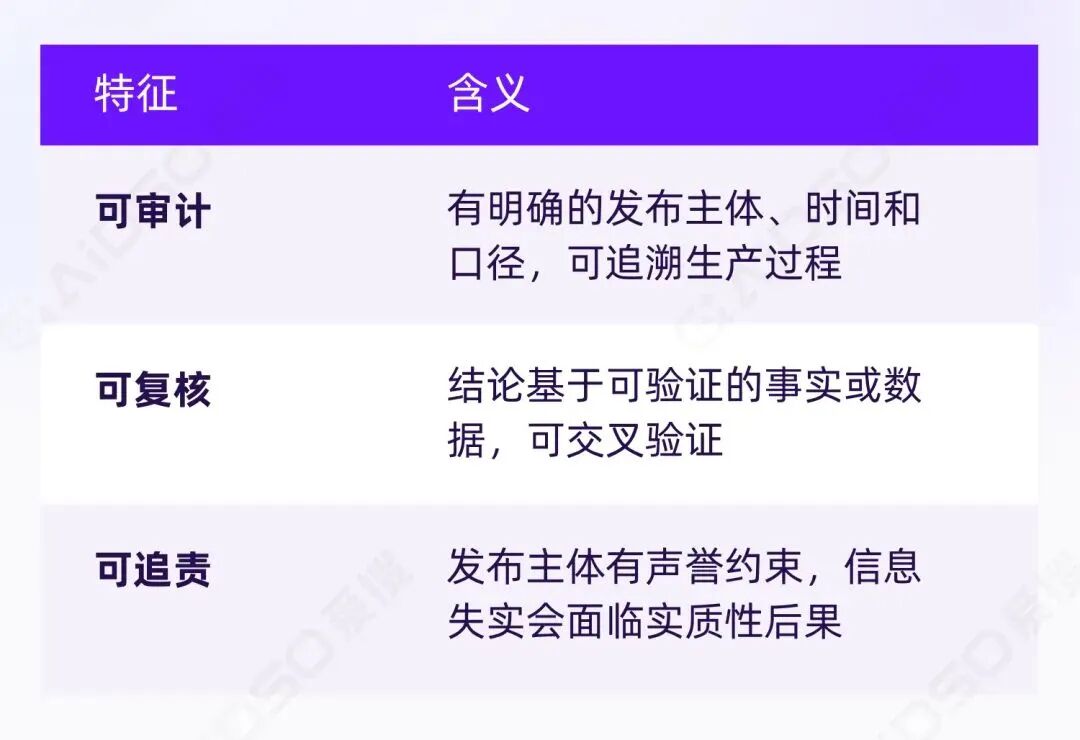
权威媒体有编辑审核机制,行业报告有方法论说明,学术机构有制度性质量控制,品牌官网代表企业正式承诺。它们的可信度不依赖于"谁转发了"或"多少人买了",而是依赖于信息本身的可验证性。
3.5 用户期待的推荐形态
理解了信任的来源之后,最后一个问题是:用户希望 AI 以什么方式给出推荐?
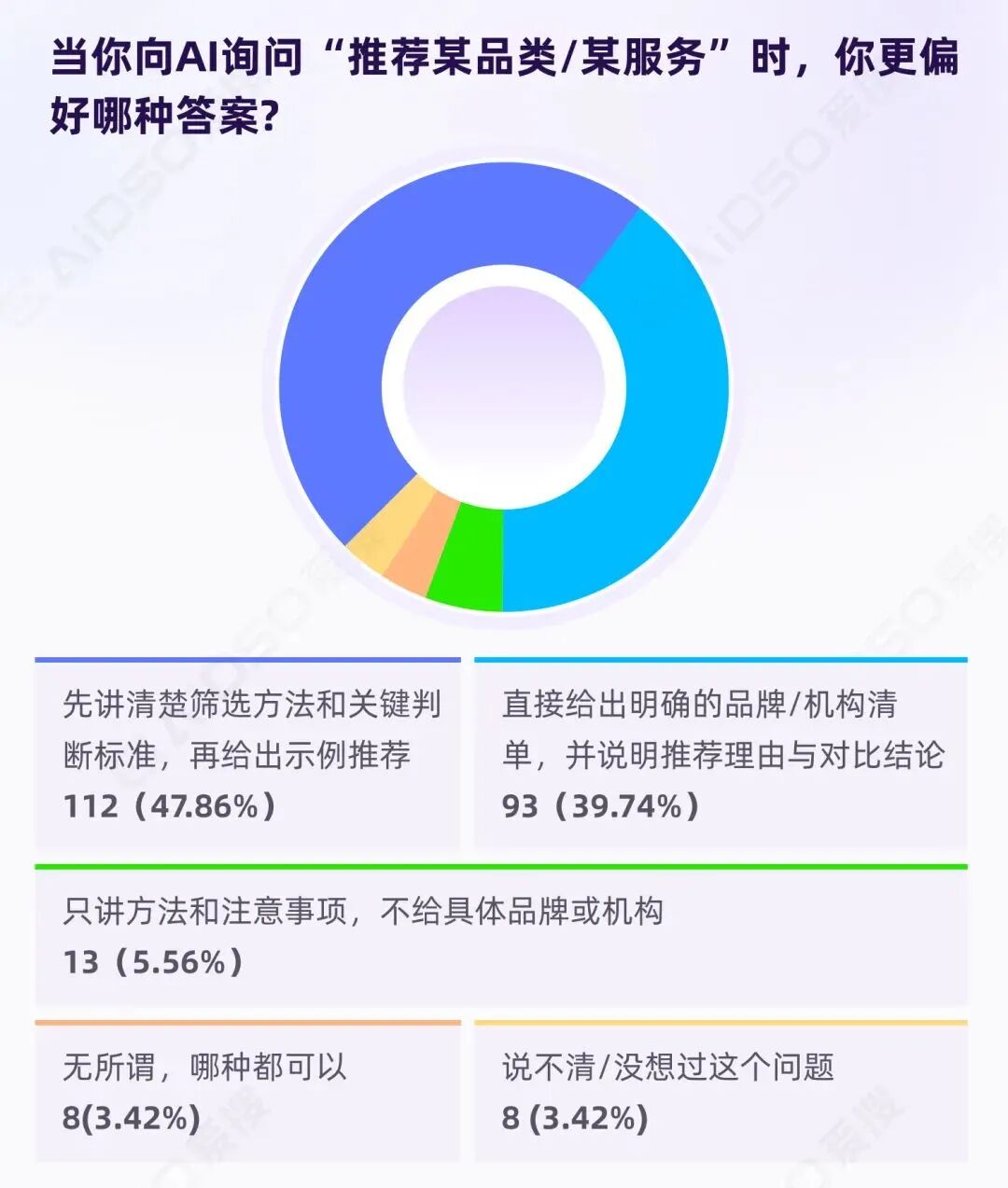
调研中请受访者选择偏好的 AI 推荐方式:
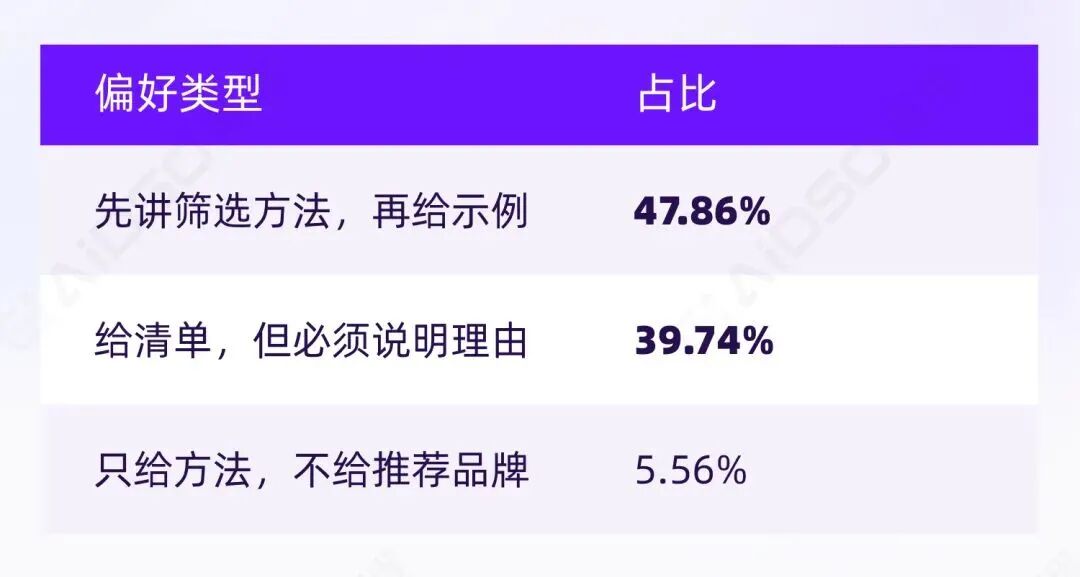
93.16%的用户明确要求 AI 在推荐时提供"方法"或"理由"。
用户要的是决策能力,不止是答案
“先讲筛选方法,再给示例"意味着用户希望 AI 先教会他们"怎么选”,获得判断能力的迁移。“给清单,但必须说明理由"意味着没有理由的推荐等同于"黑箱输出”,无法建立信任。
这与前边的发现形成闭环:81.01%的用户表示 AI 主要通过"缩小范围"和"确定评价维度"影响决策,93.16%期待推荐时提供"方法"或"理由"——用户把 AI 当作决策协作工具,而不是替代决策的黑箱。
所以对我们做 GEO 优化的启示是:
内容必须包含可被提取的筛选方法:不是"我们的产品很好",而是"选择时应关注 A、B、C 维度,判断标准是……"
每个推荐主张都必须附带可理解的理由:说明"这个特性解决什么问题"“在什么场景下更重要”
避免"直接给结论"的内容形态:没有方法和理由支撑,用户不会信任,AI 也不会优先引用

4.1 AI 是筛选器,不是替代器
当用户熟悉的品牌没有出现在 AI 回答中,用户会转向 AI 推荐的陌生品牌吗?
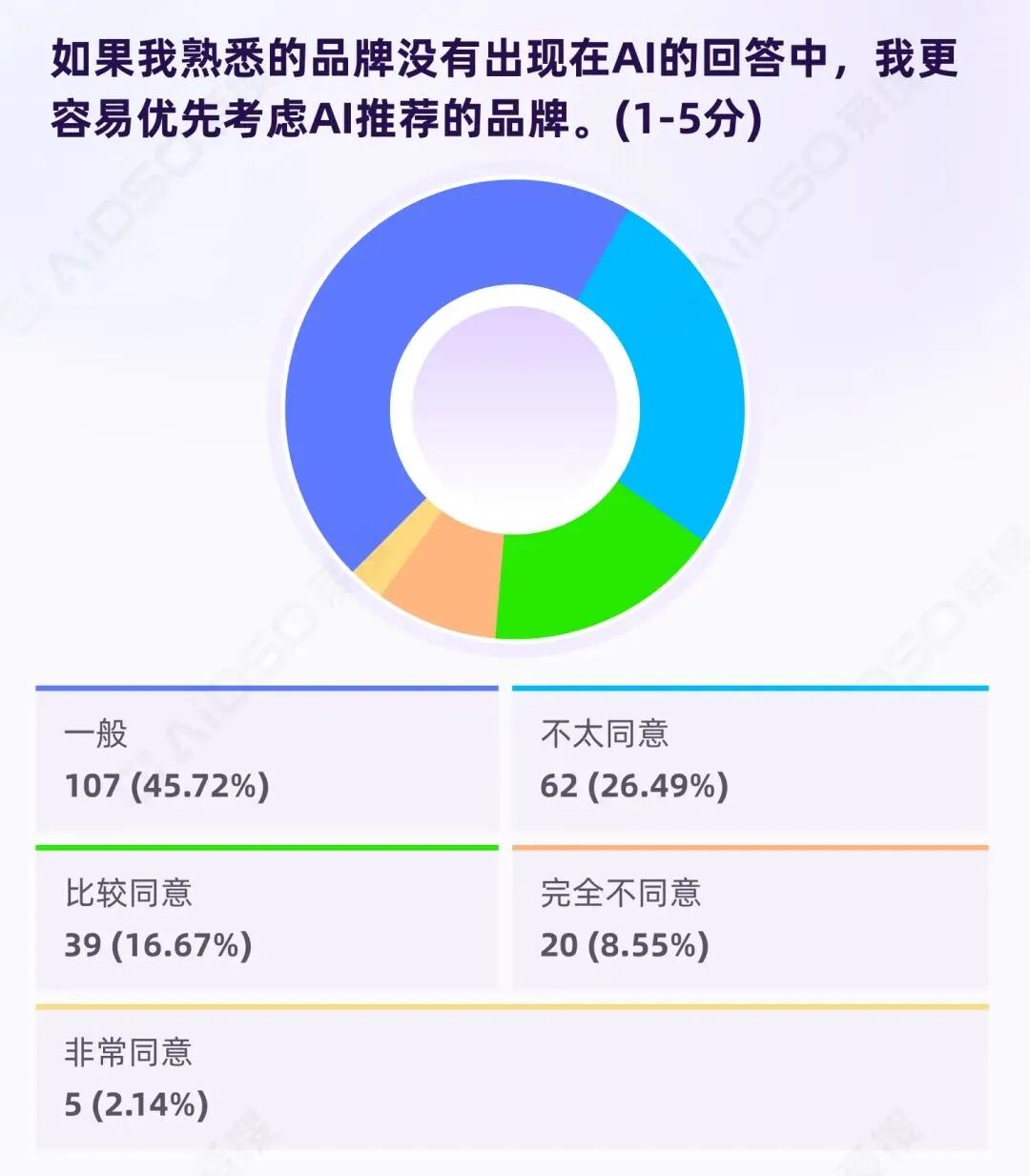
233 份有效样本显示:
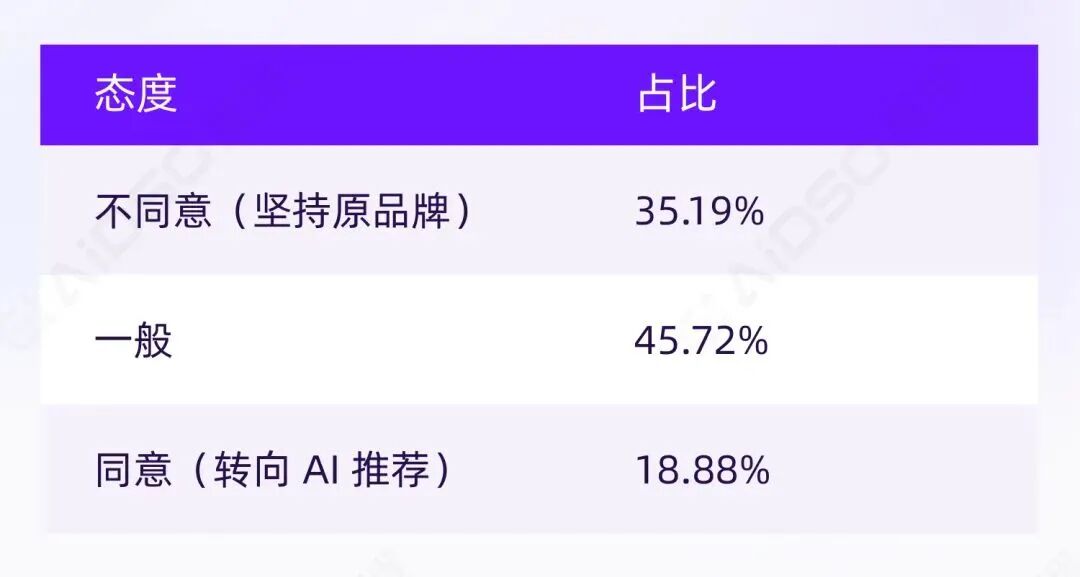
净替换倾向:18.88% - 35.19% = -16.31%
这个负值说明:
AI 推荐不能替代品牌资产。用户不会因为没看到熟悉品牌就自动倒向陌生品牌。
但真正的商业价值在中间地带。将"一般"与"同意"合并:
约 64%的人是"可被动摇人群"。他们的心态不是"我会换",而是"我愿意把 AI 推荐当成备选,重新排序"。
这与前面发现一致:AI 影响力均值 3.07/5,主要通过"缩小范围+建立评价维度"参与决策,而非直接替代。
AI 不是品牌替代器,而是品牌排序器。GEO 优化的胜负点是"抢入围、抢排序、抢比较框架"。
4.2 被 AI 推荐带来的信任加分
被 AI 推荐这件事本身,能带来多少信任加分?
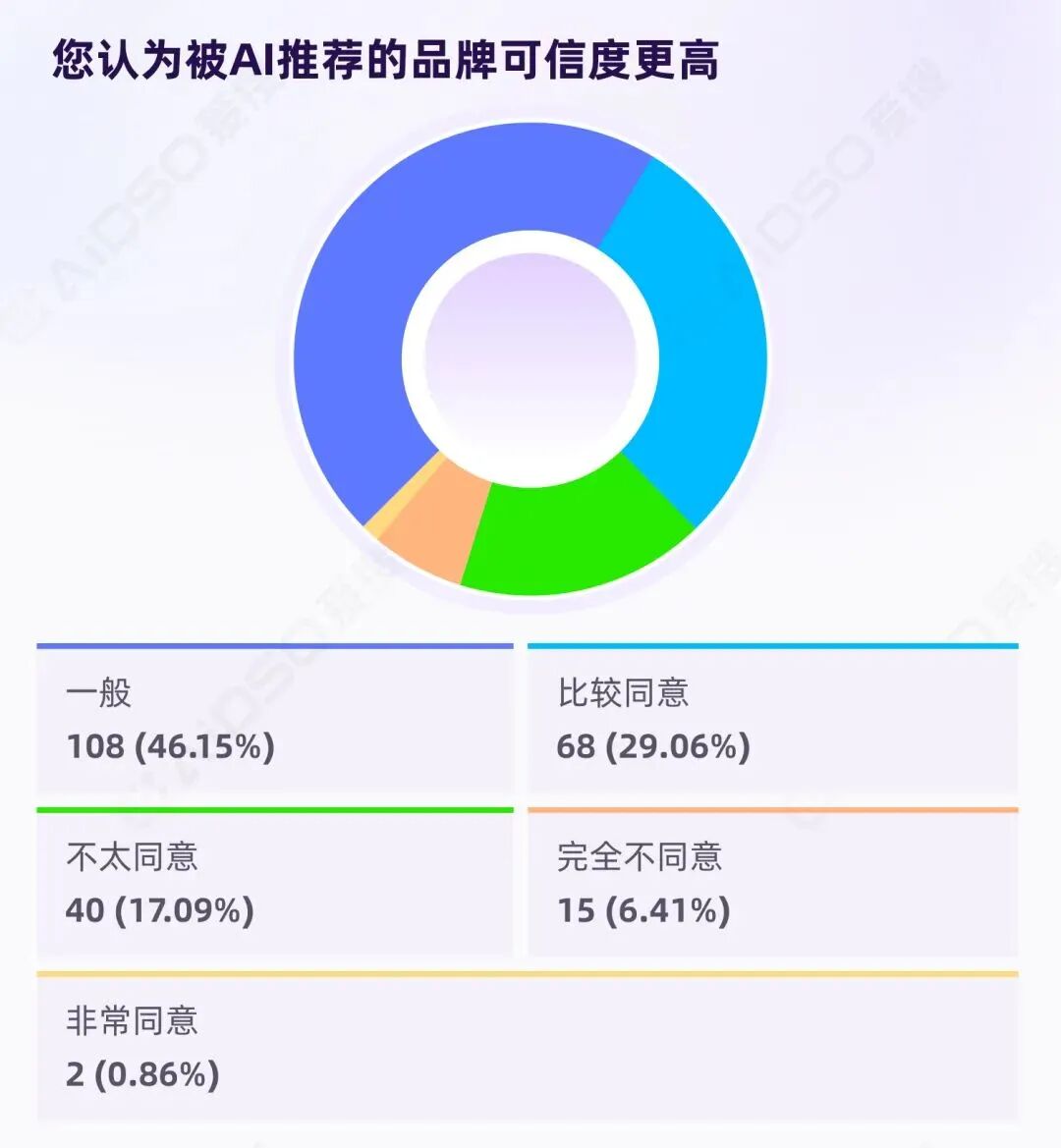
233 份有效样本显示:
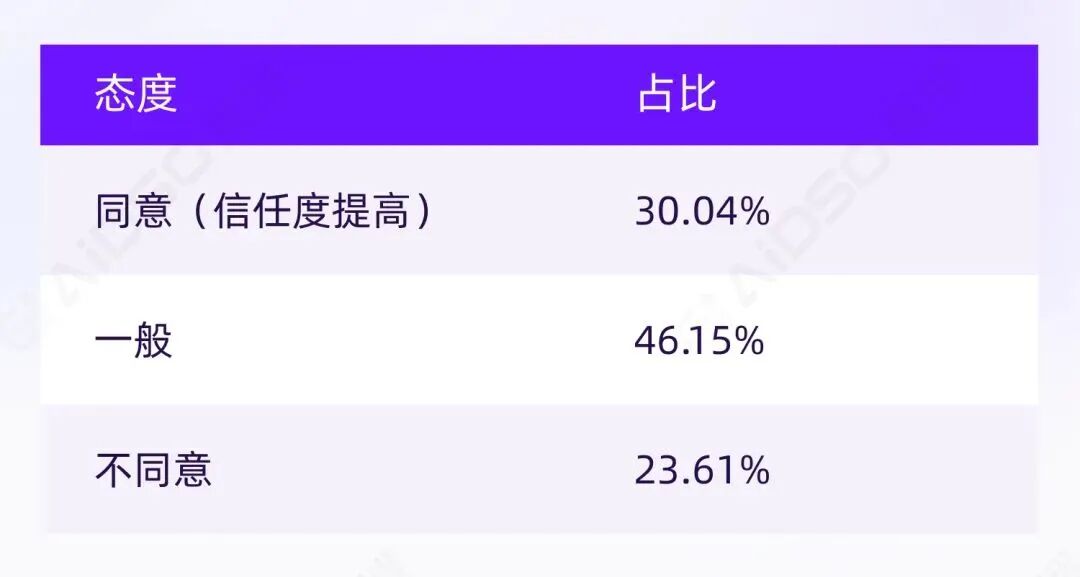
净信任溢价:30.04% - 23.61% = +6.43%
AI 推荐确实能带来信任加分,但幅度不大——远未达到"权威认证"级别。
大多数用户的态度是"先接受,再验证"——愿意把 AI 推荐当作起点,但信任建立取决于后续证据。

企业对 GEO 的认知程度如何?是否已经开始行动?
数据揭示了一个典型的"新范式扩散"图景:用户行为已大规模发生,但概念认知和组织行动严重滞后。
5.1 行为已发生,概念尚未普及
用户每天都在用 AI 搜索、接受 AI 推荐、根据引用来源建立信任——但他们是否知道,这套环境可以被系统性管理吗?
GEO 概念认知刚过半数
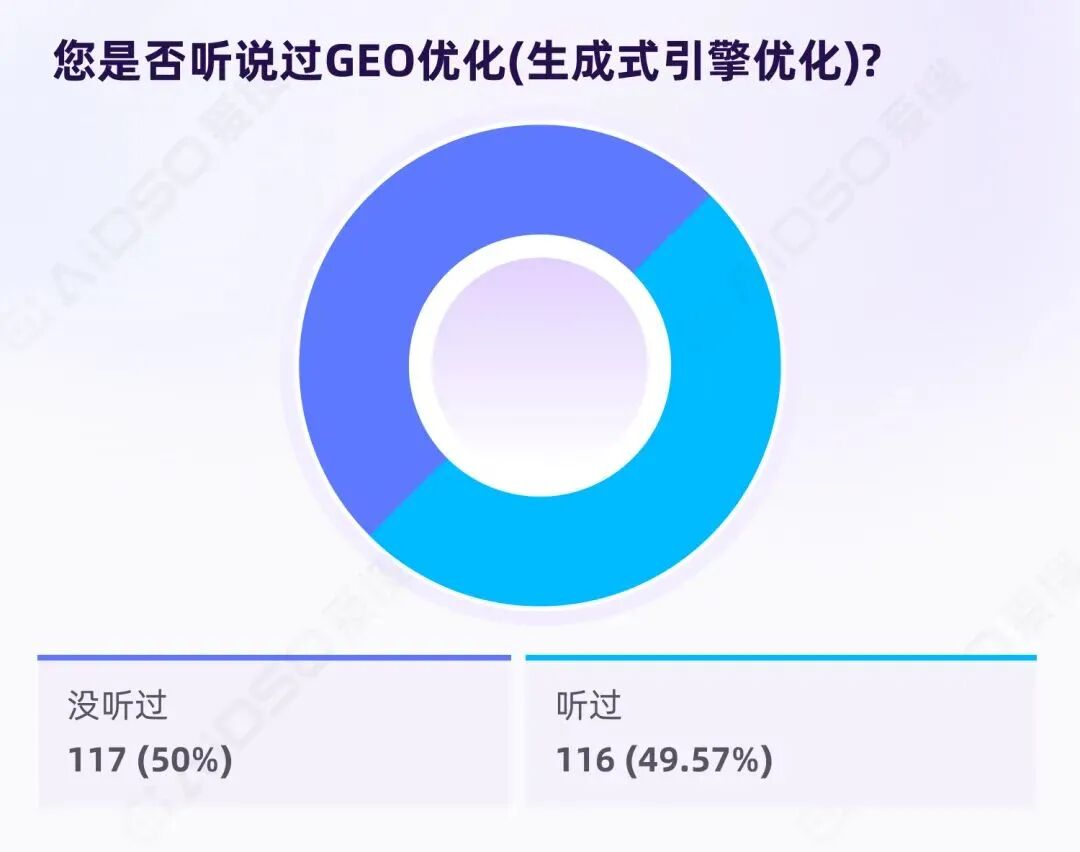
233 份有效样本中:
听说过 GEO:49.57%
未听说过 GEO:50.00%
这个 50:50 的分布,呈现出典型的"早期多数"阶段特征:概念已突破早期采用者圈层,但尚未成为普遍常识。
错位现象:身处其中,却不自知
将这一发现与前四章数据联动,错位清晰可见:
98.72%的用户每天至少使用一次 AI 搜索
86.70%的用户会被 AI 推荐影响
81.62%的用户会查看 AI 回答的引用来源
但只有 49.57%听说过 GEO
超过一半的用户每天都在被 GEO 影响,却不知道"GEO"这个概念存在。他们是 GEO 的作用对象,但不是认知主体。
这个错位既是挑战也是机会——当竞争对手还在犹豫时,率先行动者可获得显著先发优势。
5.2 品牌 AI 可见度已进入关注视野
虽然 GEO 概念尚未普及,但一个相关行为已悄然发生:用户开始主动观察品牌是否被 AI 提及。
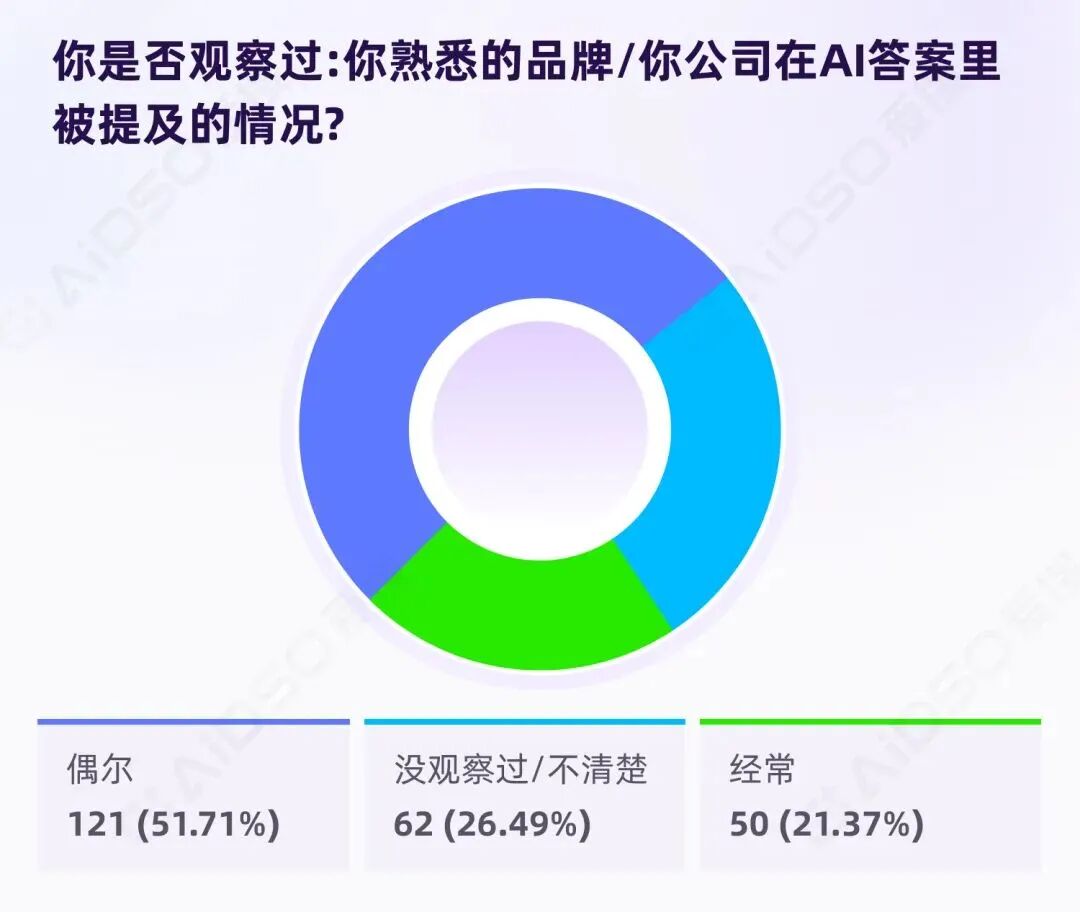
73.08%的用户至少偶尔观察过品牌的 AI 可见度。
这个观察率远高于 GEO 概念认知率(49.57%),说明行为已领先于概念——人们在做这件事,只是还没给它起个名字。
如果你从未系统看过自己或竞品在 AI 中的曝光情况,我们做了一个小程序,可一键查看品牌与竞品在主流 AI 场景下的可见度对比,先看清位置,再谈下一步。

5.3 组织讨论与行动的断层
概念认知和行为观察都在发生,但企业内部是否已开始行动?
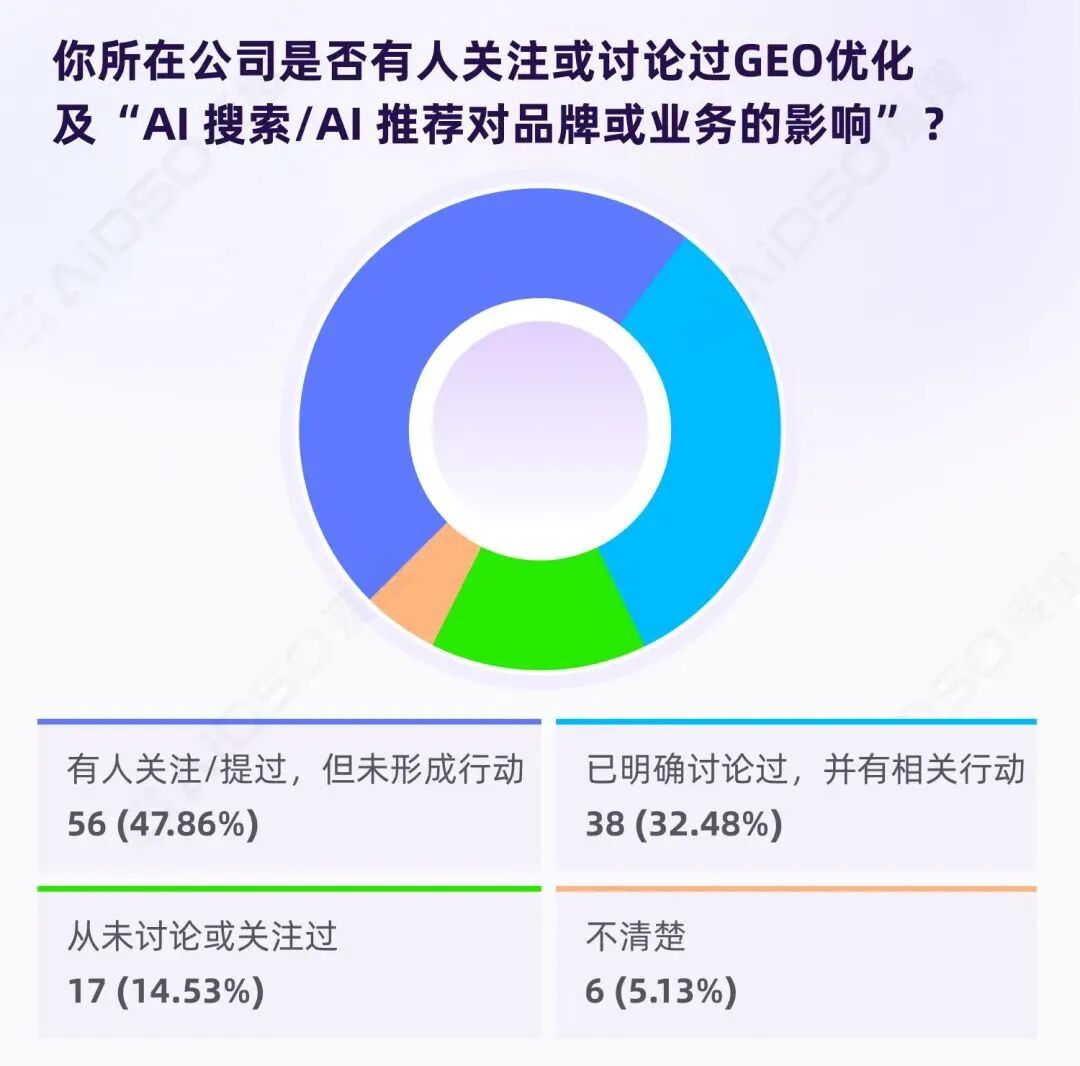
仅 32.48%有明确行动,近半停留在"提过但未行动"
117 份有效样本中(仅统计听说过 GEO 的受访者):
有明确行动:32.48%
提过但未行动:47.86%
从未讨论/不清楚:19.66%

超过 80%的组织讨论过 GEO,但只有 32%有明确行动。讨论热烈,行动迟缓——中间到底卡住了什么?
6.1 核心阻力:可证明性危机
我们直接问受访者:推进"AI 可见度提升"的最大阻力来自哪里?
答案出人意料地集中:
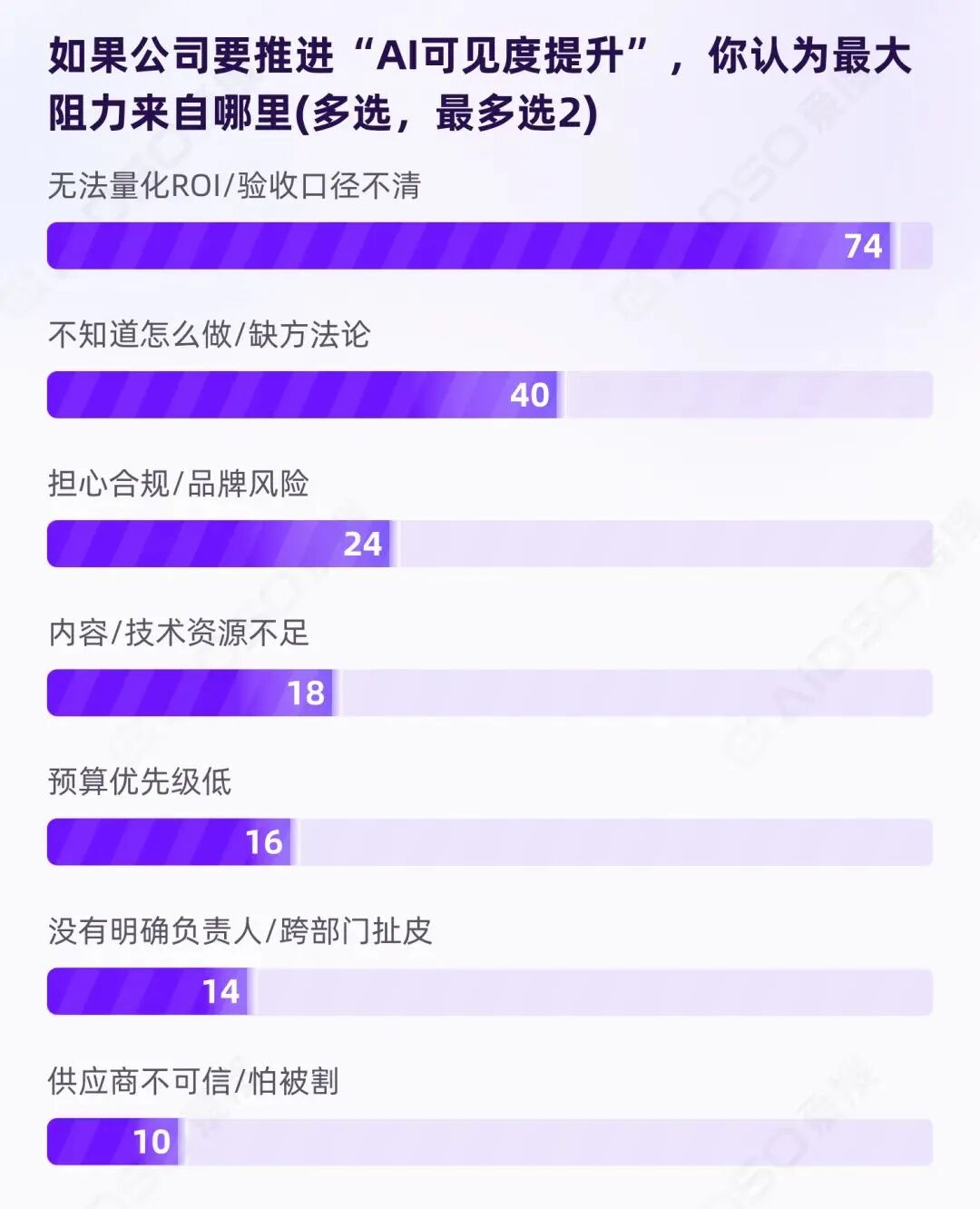
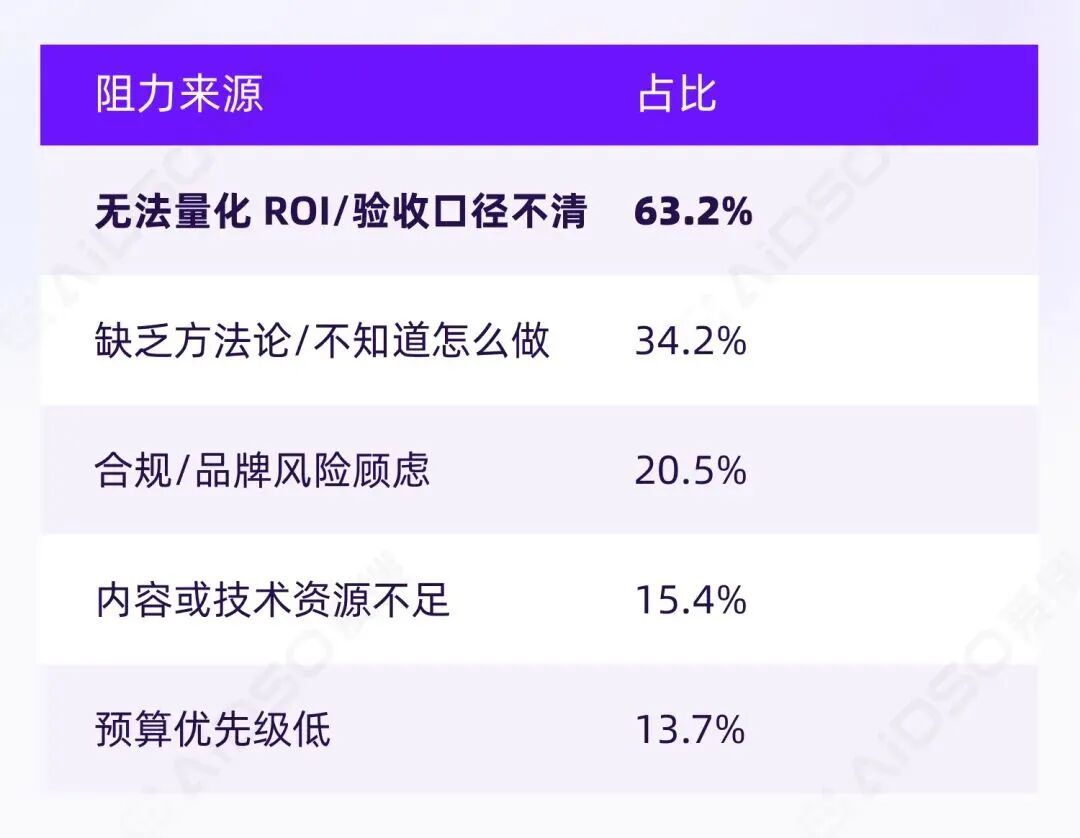
63.2%——近三分之二的受访者指向同一个问题:无法量化 ROI。
这直接否定了"企业不愿意为 GEO 投钱"的判断。真实情况是:当一项工作无法被清晰验收时,预算自然无法被合理安排。问题的起点不在"要不要做",而在"做成什么算数"。
第二大阻力"缺乏方法论"(34.2%)与此形成恶性循环:因为不知道怎么衡量效果,所以不知道什么方法有效;因为不知道什么方法有效,所以无法建立效果衡量体系。
值得注意的是,“预算优先级低”"没有明确负责人"等选项均不足 15%。这说明:一旦验收口径与方法路径清晰,组织意愿层面的障碍往往会自然消解。
6.2 验收标准:三种逻辑并行的分歧
可证明性危机的背后,是验收标准的分歧。我们询问受访者认为哪些结果可以作为 GEO 的"可接受验收标准":
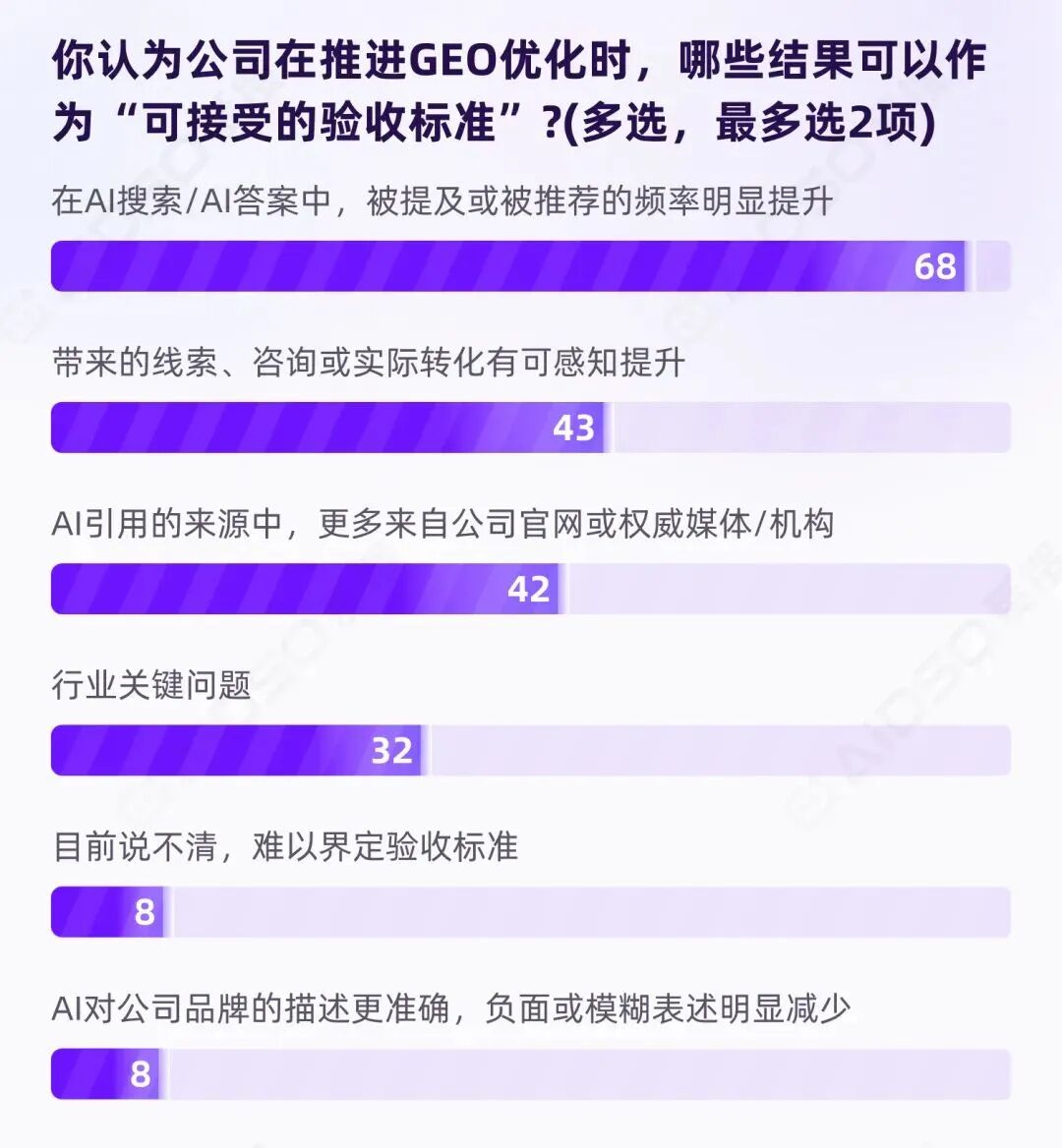
数据呈现"三轨并行"格局:
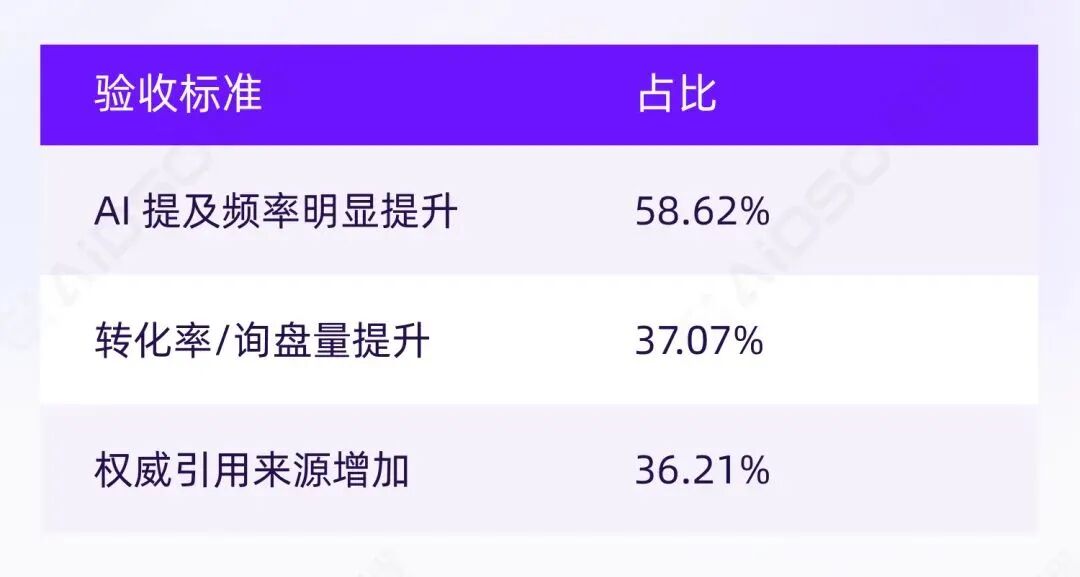
曝光逻辑(58.62%) 占据主流,表明多数企业已完成关键认知转移:GEO 优化不再以传统 SEO 的"排名"为目标,而是以"是否进入 AI 回答视野"为第一性判断。
转化逻辑(37.07%) 紧随其后,说明 GEO 已被纳入增长部门视野——AI 提及是手段,商业结果才是目的。
过程审计(36.21%)关注的是"权威引用来源增加",本质上是一种工作量验收思维:创作了多少符合 GEO 优化逻辑的内容?这些内容是否被 AI 引用?
企业已普遍接受用曝光逻辑衡量 AI 认知资产,用转化逻辑要求商业回报,并且要求对过程进行审计
没有任何一个标准获得压倒性认可(最高仅 58%),这意味着组织在启动 GEO 优化项目时,必须先在内部对齐验收标准——否则项目结束时,不同部门对"是否成功"的判断可能截然相反。
6.3 预算归属:品效之间的灰色地带
验收标准的分歧,进一步导致预算归属的模糊。我们询问受访者认为 GEO 预算应该归入哪个部门:
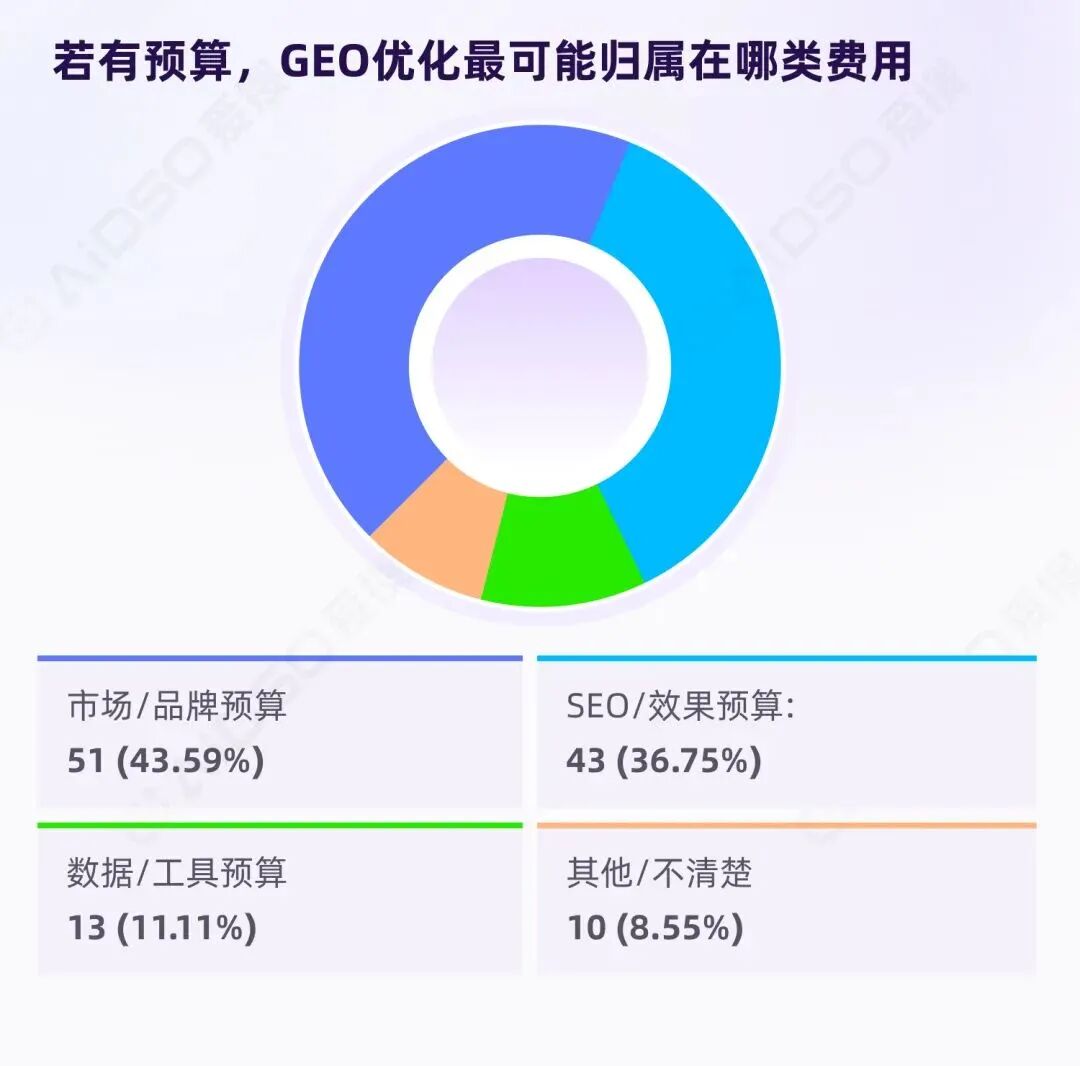
80.34%将 GEO 归入既有营销费用框架,说明 GEO 并未被视为需要单独新设的预算科目。
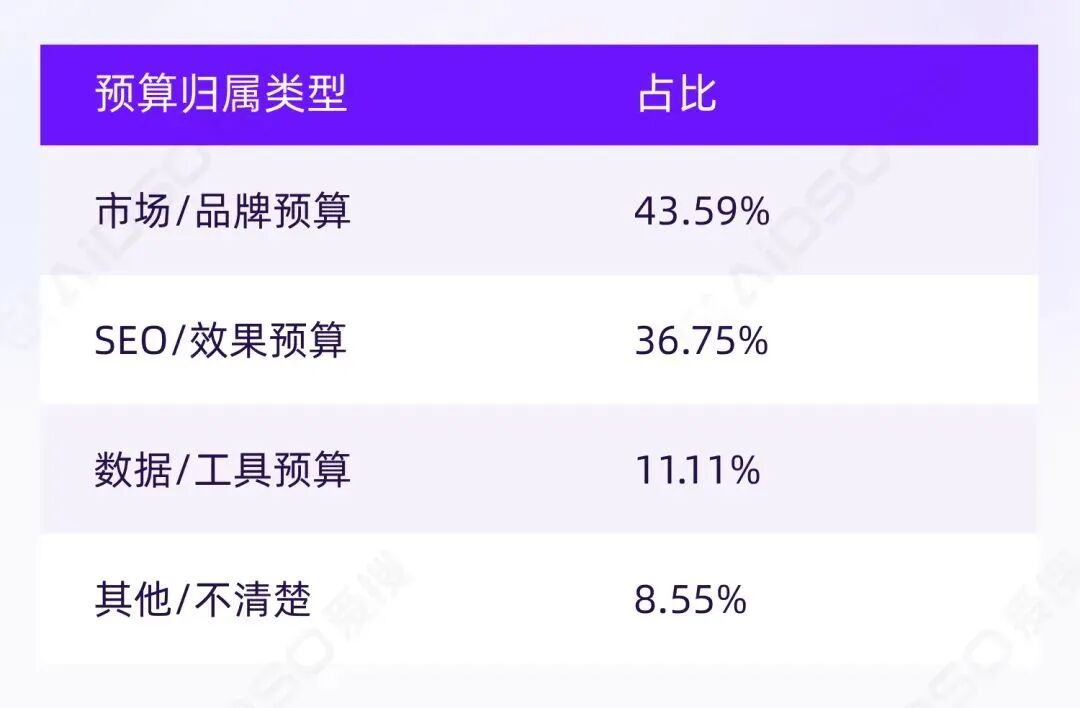
但"品牌预算"与"效果预算"的接近比例(43.59% vs 36.75%),揭示了 GEO 的定位困境:
GEO 天然处于"品效合一"的拉扯中——一端是长期的认知与信任积累,另一端是短期的效率与结果导向。
这种并列关系在组织内部往往意味着"品效都不管":
品牌团队可能认为:“这是 SEO 的变种,应该效果团队负责。”
效果团队可能认为:“AI 提及不能直接归因转化,这是品牌的事。”
结果是 GEO 成为两个部门之间的灰色地带,缺乏明确责任主体。
仅 11.11%归入"数据/工具预算",说明多数企业并不认为"购买工具"能解决 GEO 核心问题,而更倾向于将其理解为内容与运营层面的持续动作。
这反映出 GEO 优化在组织内的现状:尚未完成稳定归口,它被讨论、被感知,但尚未形成"谁拍板、谁出钱、怎么考核"的明确共识。

7.1 开放反馈揭示的五类底层诉求
问卷最后一题,是开放式问题,揭示了五类反复出现的底层诉求:

第一类:信任与真实性诉求
“希望数据真实可信,不是光凭钱获得曝光度”
“提高 AI 引用搜索来源的可靠性”
用户担心的不是 AI 不推荐,而是 AI 被"投喂"低质营销内容后推荐质量下降。信任不是加分项,是准入门槛。
第二类:ROI 量化焦虑
“ROI 量化标准怎么具有说服力”
“担心财务和精力的投产比低”
“主要是效果的量化”
这是出现频率最高的诉求,与前边 63.2% 将"无法量化 ROI"列为最大阻力完全同源。很多从业者不是不想做,是不敢做——无法承担"投入了但证明不了效果"的职业风险。
第三类:方法论缺失
“应该有一个具体操作的执行模板”
“不知道怎么拿到结果”
对应第二大阻力(34.2%)。市场充斥着"为什么要做 GEO"的内容,但缺乏"怎么做"的实操指南。GEO 优化尚未从概念产品化为可照抄流程。
第四类:付费意愿与"被割"警惕
“希望有高性价比的相关课程”
“我们愿意为此付费”
“能割韭菜的风口要抓住”
用户愿意付费换确定性,但对"被割韭菜"高度警惕。这是一群清醒但焦虑的早期采用者。
第五类:案例优先于理论
“如果能多提供拿到结果的案例,我们愿意付费”
“给出实际案例”
一旦"别人能做到"被证明,预算和行动自然发生。案例不是营销素材,是替用户做风险评估的工具。
7.2 GEO 的核心竞争定义
综合前文发现,可以重新定义 GEO 竞争的本质:
GEO 优化竞争的不是曝光,而是入围权、评价框架话语权与可引用内容体系。
第一层:入围权竞争
通用对话式 AI 已覆盖 91% 人群。品牌不在 AI 回答中出现,就失去进入用户考虑集的机会。GEO 优化首先要确保不被系统性遗漏。
第二层:评价框架话语权
“缩小范围"与"确定评价维度"合计占 81% 的影响方式。AI 不只筛选对象,还在定义"应该怎么选”。真正有效的 GEO 优化策略不是强调"我们很强",而是让 AI 学会:在这个品类里,哪些维度应该被优先考量。
第三层:可引用内容体系
81.62% 用户在意引用来源,87.6% 偏好"既给方法又给推荐"。GEO 优化要建立满足三个条件的内容体系:可审计、可复核、高权威。

98.72%的用户每天使用 AI 搜索,86.70%会被 AI 推荐影响,81.62%会查看引用来源——AI 可见性已成为品牌增长的关键战场。
然而,63.2%的企业将"无法量化 ROI"列为推进 GEO 的最大阻力。企业甚至不知道自己在 AI 世界里是"被看见"还是"隐形"。AIDSO 爱搜正是为解决这一问题而生。
AIDSO 爱搜通过对接豆包、DeepSeek、腾讯元宝、百度AI、文心、千问、Kimi 、AI抖音八大主流 AI 平台,围绕三个核心场景为品牌提供支持:快速诊断当前状态、持续监控动态变化、系统掌握优化方法。
8.1 快速搜索:单点穿透,即时诊断
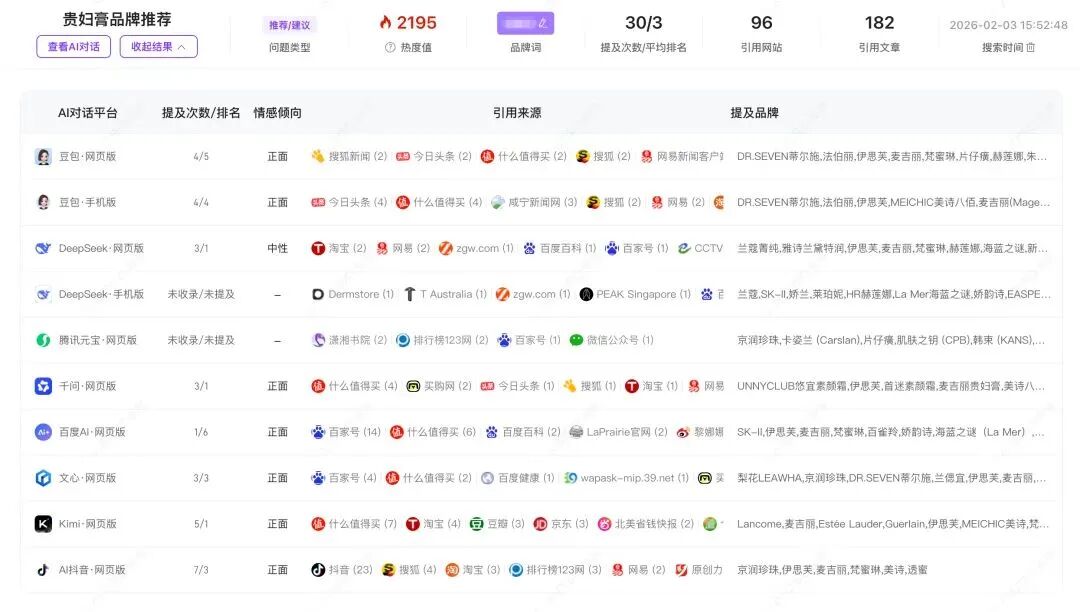
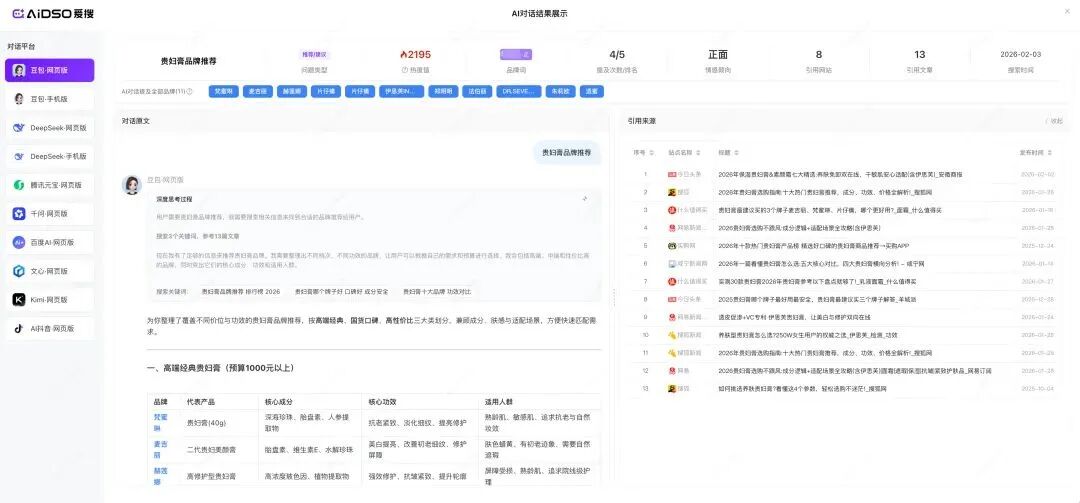
快速搜索是最直接的诊断入口。输入一个真实用户问题,比如"北京装修公司推荐"或"性价比羽绒服品牌推荐",系统会模拟真实用户向八大 AI 平台同时提问,然后将所有回答汇总呈现。
结果页会告诉你:每个平台提到了哪些品牌、你的品牌被提及多少次、在推荐列表中排第几、AI 对品牌的情感倾向如何。如果你的品牌在大部分平台提及次数为零,说明当前在 AI 世界里几乎隐形,GEO 优化必须从"被看见"开始。
快速搜索的本质是单点穿透——用一个真实问题,一次性看清不同 AI 平台的差异化表现,快速定位问题所在。
8.2 品牌监控:持续追踪,长期体检
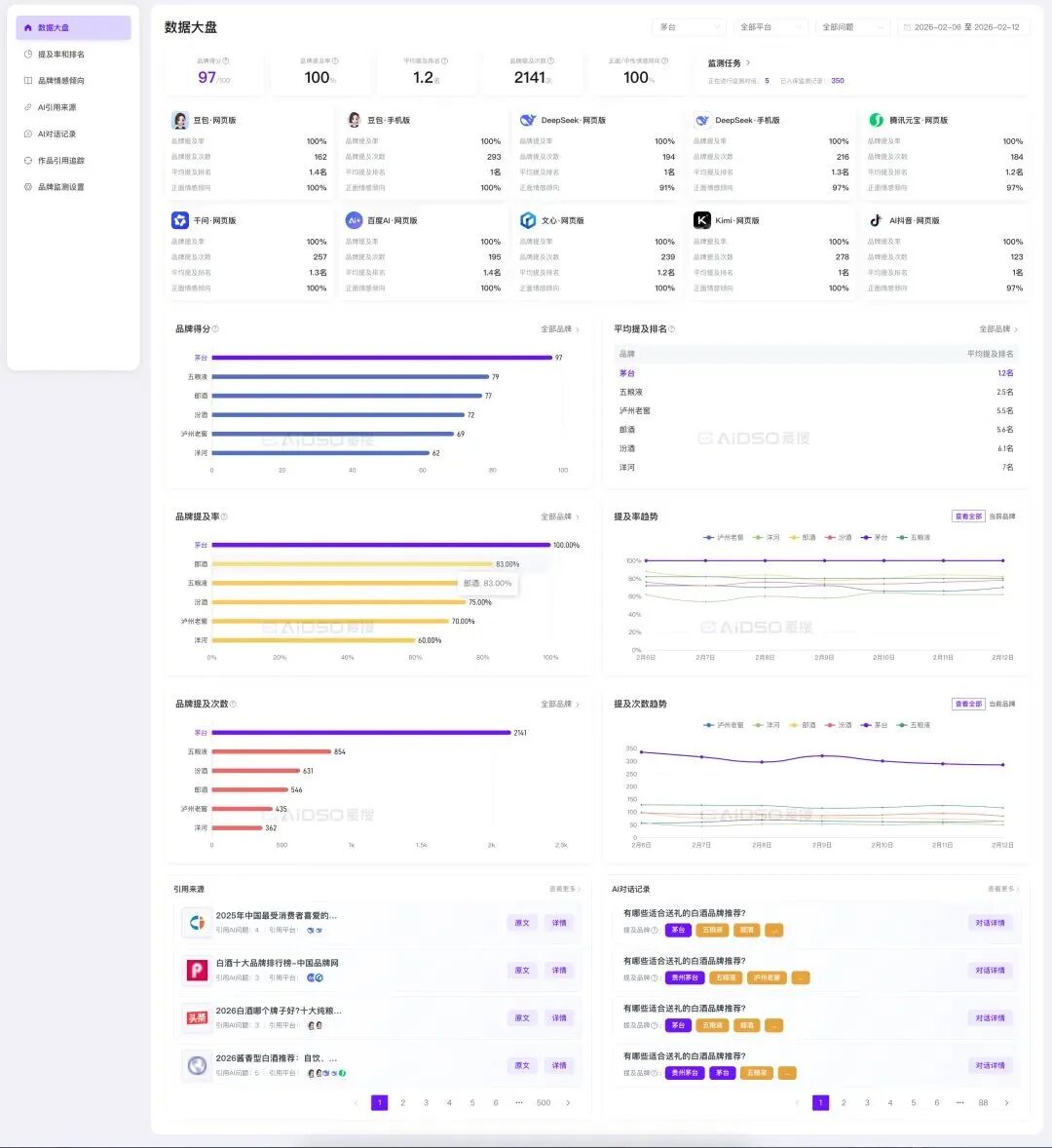
如果说快速搜索解决的是"此刻状态",品牌监控解决的则是"持续追踪"。
GEO 优化不是一次性动作,而是需要周期性体检的长期工程。品牌监控功能允许企业设定关注的品牌、竞品和问题集合,系统会持续抓取各平台的 AI 回答,生成数据大盘。
数据大盘呈现的是品牌 AI 健康度的全景:综合得分、提及率、平均排名、情感倾向的变化曲线。同时,系统还会追踪 AI 引用了哪些内容来源——这直接回答了"AI 的判断依据是什么",帮助品牌找到应该优先布局的内容阵地。
8.3 游学陪跑:从"不知道怎么做"到体系落地

调研显示,34.2%的企业将"缺乏方法论/不知道怎么做"列为推进 GEO 的核心障碍。工具再强大,如果不知道如何将监控结果转化为优化动作,品牌仍然难以真正启动。
游学陪跑项目正是为此设计的系统化培训,帮助品牌完成从认知到执行的全链路闭环。
核心内容覆盖四个模块:
原理认知——理解 GEO 优化的实现原来,掌握 AI 引用的底层判定逻辑;
诊断实操——现场使用平台完成品牌自检、竞品分析、引用源追踪;
内容方法论——拆解高引用内容的结构规律,掌握可复用的 GEO 内容模板;
效果验证——建立监控-优化-复盘的完整闭环,形成整套系统方法论。
AIDSO 爱搜为品牌提供的,是让 AI 从"不知道会说什么"的黑箱,变成可理解、可监测、可优化的认知渠道。
快速搜索让诊断即时化,品牌监控让追踪持续化,游学陪跑让方法体系化——三者结合,品牌在 AI 可见性战争中,从盲人摸象走向有据可依、有法可循。

回到开篇的问题:流量从哪里来?
二十年间,搜索从 SEO 到 ASO 再到 DSO,每一次迁移都重写规则。而今天,GEO 时代已经到来。
234 份样本告诉我们的结论,比预想更清晰,也更紧迫:
迁移已经发生。 98.72%的用户每天使用 AI 搜索,91%被通用对话式 AI 覆盖。这不是趋势,是现实。
规则正在重写。 86.70%的用户决策被 AI 影响,但方式不是"替人拍板",而是"缩小范围"与"确定评价维度"。竞争焦点从"谁排第一"变成"谁能进入候选名单"、“谁能定义比较规则”。
信任被重新定义。 81.62%的用户查看引用来源,权威媒体与官网成为信任锚点。可审计、可复核、可追责——这是 AI 时代的信任货币。
行动严重滞后。 仅 32.48%的企业有明确行动,63.2%卡在"无法量化 ROI"。用户每天被 GEO 影响,大多数企业还在犹豫是否开始。这种滞后,既是挑战,也是窗口。
说实话,这种滞后,既是挑战,也是窗口。
但问题是:第一步怎么迈?
去年我和很多品牌聊过,大家的困惑出奇一致——不是不想动,是不知道自己现在在哪。
所以我们做了一个小工具。输入你的品牌名称,系统自动查询你和竞品在主流 AI平台的可见度表现,2分钟秒出结果。
👇 扫码体验「AI 可见度 PK」

先看清自己的位置,再决定下一步怎么走。
GEO 的本质,不是又一轮流量游戏,而是在 AI 时代重建品牌认知资产。过去二十年,我们学会了"如何被搜索引擎看见"。未来十年,我们要学会的是"如何被 AI 理解与信任"。
搜索的形态在变,但底层逻辑从未改变:谁能持续提供可信赖的答案,谁就拥有流量。
GEO 时代,你,准备好迎接了嘛?











